
操作系统
导论
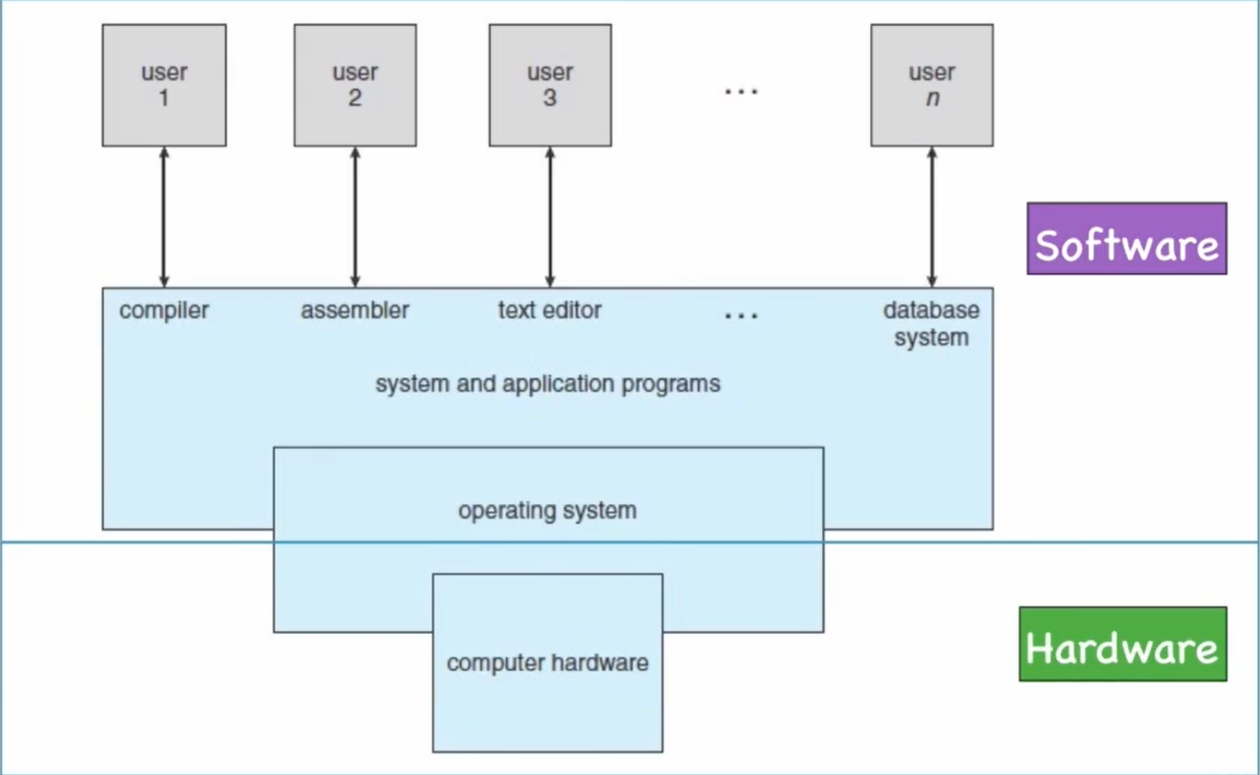
计算机系统层次结构
INTERFACE(接口,界面,介面)
接口是连接两个物体的边界,通过这个界面两边都可以很好的对话
- 硬件-软件: usb, VGA, HDMI
- 软件-硬件: Instructions(指令集)
- 软件-软件: Application Programming Interface (API)
VIRTUAL MACHINE
操作系统向用户提供一个容易理解和使用的 “计算机”(虚拟的), 用户对这个”计算机”的操作都将被操作系统转成对计算机硬件的操作。
主引导扇区(BOOT SECTOR)
- 硬盘的
0柱面 ,0磁头,1扇区称为主引导扇区,在这扇区里存放着一段代码:主引导MBR(Main Boot Record),它用于硬盘启动时将系统控制权转给用户指定的 在分区表中登记了某个操作系统分区 - MBR的内容是在硬盘分区时由分区软件写入该扇区的,MBR不属于任何一个操作系统,不随操作系统的不同而不同,即使不同,MBR也不会夹带操作系统的性质,具有公共引导的特性
BOOTSTRAP OF COMPUTER
- 打开电源
CPU将控制权交给BIOS(基本输入输出系统,存放在CMOS中)BIOS运行一个程序: 通电自测试程序BIOS确认所有外部设备: 硬盘或扩充卡BIOS找到磁盘的引导区,将其中的主引导程序1bootloader装入内存。(主引导程序是一段代码,它可以将OS余下部分装入内存)- 引导操作系统结束,操作系统接管计算机
- 操作系统等待时间发生……
中断
- 当有事件(
Event)发生时,CPU会收到一个中断(Interpret)信号,可以是硬中断也可以是软件中断。 CPU会停止正在做的事,转而执行中断处理程序,执行完毕会回到之前被中断的地方继续执行- Operating System is an INTERRUPT driven system.
STORAGE SYSTEM(存储系统)
CPU负责将指令(Instruction)从内存(Memory)读入,所以程序必须在内存中才能运行。- 内存以字节为储存单位,每个字节都有一个地址与之对应。通过load/store指令即可访问指定地址的内存数据:
load: 将内存数据装入寄存器(Register)store: 将寄存器数据写入内存
分时系统
- 分时系统(
time sharing)也称多任务系统(multi-tasking),是多道程序设计的自然延生。 - 允许多个用户共享一台计算机
- 用户只有输入和输出设备
- 分时系统为每个用户轮流分配等量的
CPU时间 - 用户从发出指令到得到即使结果的时间称为响应时间
- 第一个分时系统
CTSS由MIT于1962年开发出来
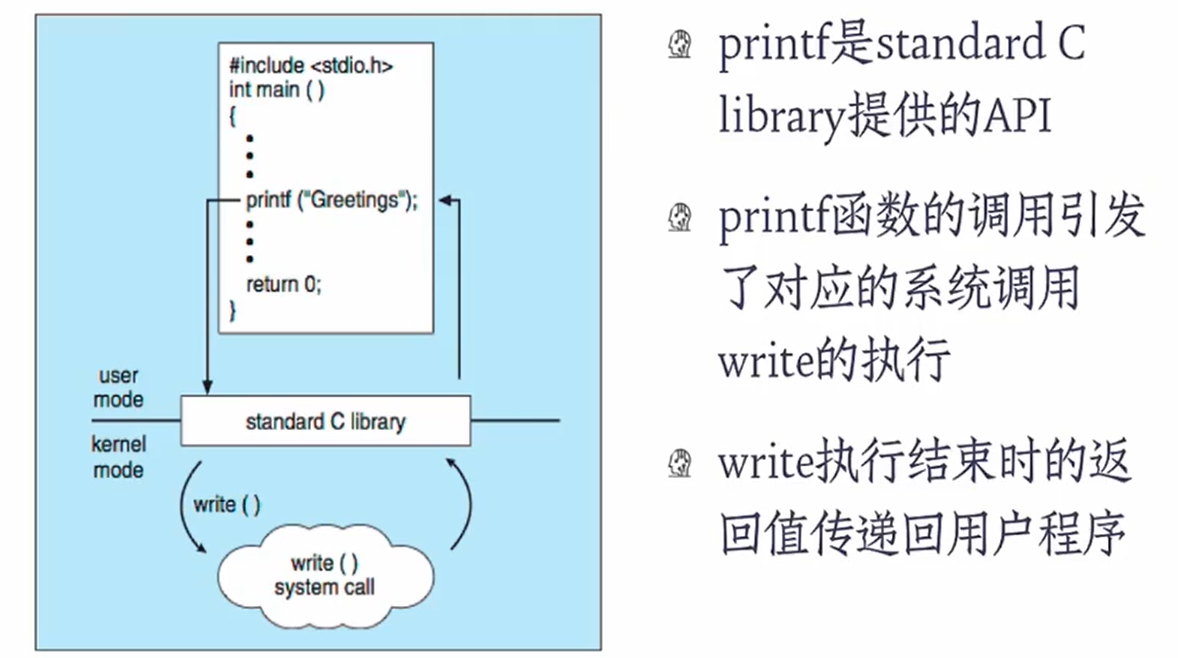
系统调用(SYSTEM CALLS)
- 系统调用提供了访问和使用操作系统所提供的服务的接口
- 系统调用的实现代码是操作系统级的
- 这个接口通常是面向程序员的
- API(Application Programming Interface): 指明了参数和返回函数的一组函数
- 应用程序App的开发人员通过透过API间接访问了系统调用
- Windows API/ POSIX API
双重模式(DUAL MODE)
- 现代计算机系统有一个特殊的硬件,用于划分系统的运行状态,至少需要两种单独运行模式:
用户模式(user mode): 执行用户代码内核模式(kernel mode): 执行操作系统代码
- 实现方式
- 用一个硬件模式位来表示当前模式:
0代表内核模式,1代表用户模式
- 用一个硬件模式位来表示当前模式:
进程
进程的定义
- 进程是一个程序的一次执行过程
- 能完成具体的功能
- 能在某个数据集合上完成的
- 执行过程是可并发的
- 进程是资源分配,保护和调度的基本单位
程序和进程
- 程序是一个被动的实体, 例如存储在磁盘上的包含一系列指令的文件(经常称为可执行文件)
- 当可执行文件被加载进内存后,这个程序就会变为一个进程
- 一个进程是一个活动的实体,包含一个程序计数器用来指明下一条要执行的指令以及一组相关的资源
PROCESS IN MEMORY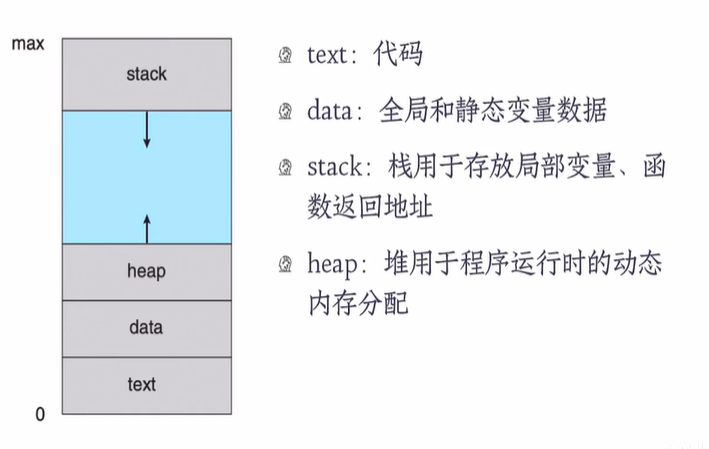
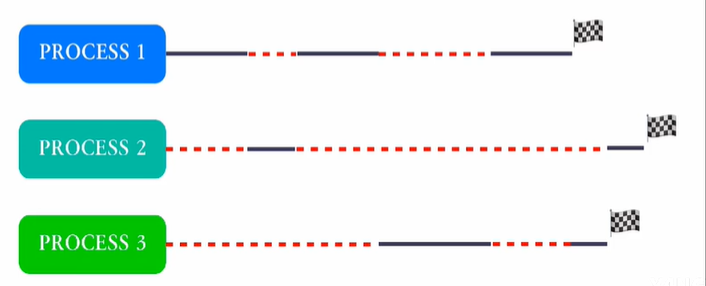
并发的进程
Concurrency: the fact of two or more events or circumstances happening or existing at the same time
并发进程可能无法一次性执行完毕,会走走停停
一个进程在执行过程中可能会被另一个进程替换占有CPU,这个过程称作 “进程切换”
进程的状态
进程状态(PROCESS STATE)
- 进程在执行期间自身的状态会发生变化,进程有三个基本状态,分别是:
运行态(Running): 此时进程代码在CPU上运行就绪态(Ready): 进程具备运行条件,等待分配CPU等待态(Waiting): 进程在等待某些事件的发生(比如IO操作结束或是一个信号)
进程何时离开CPU
- 内部事件
- 进程主动放弃(yield)CPU,进入等待/终止状态
- 使用 I/O设备,(非)正常结束
- 外部事件
- 进程被剥夺CPU使用权,进入就绪状态。这个动作叫抢占(preempt)
- 时间片到达,高优先权进程到达
进程的转换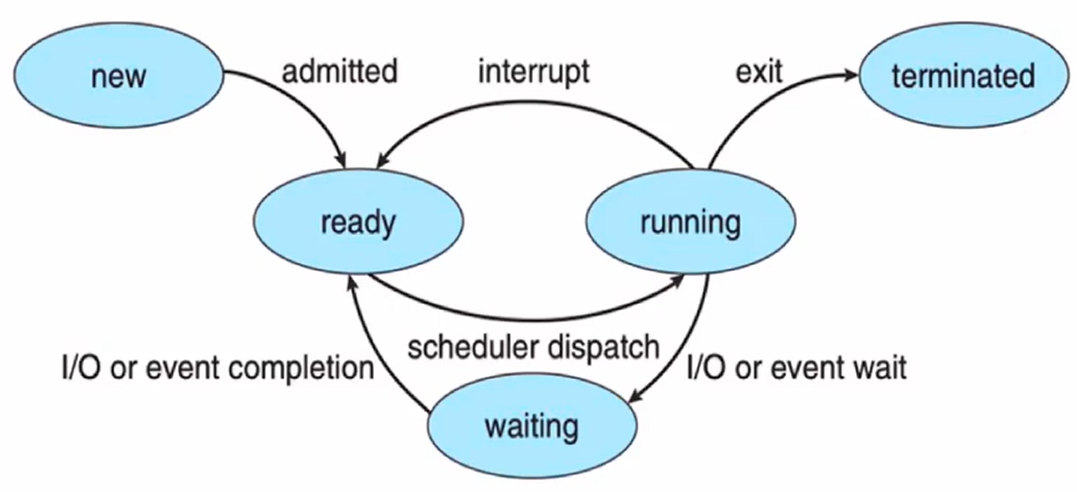
进程切换
并发进程的切换
并发进程中,一个进程在执行过程中可能会被另一个
进程替换占有CPU,这个过程称作“进程切换”
中断技术
中断是指程序执行过程中:
- 当发生某个事件时,中止CPU上现行程序的运行
- 引出该事件的处理程序执行
- 执行完毕返回源程序中断点继续执行
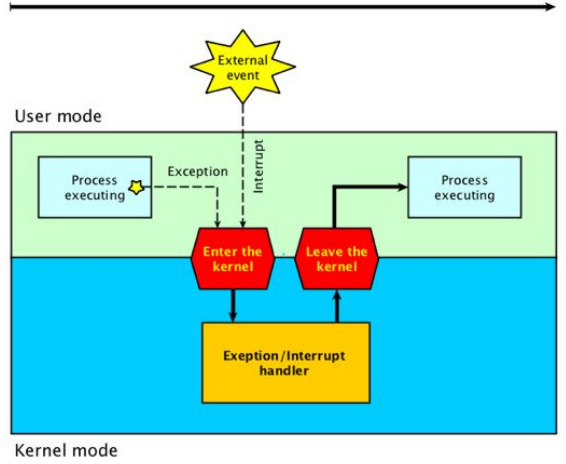
中断源
- 外中断(
Interrupt): 来自处理器之外的中断信号- 如时钟中断,键盘中断,外围设备中断
- 外部中断均是异步中断
- 内中断(
异常Exception): 来自处理器内部,指令执行过程中发生的中断,属于同步中断- 硬件异常: 掉电,奇偶校验错误等
- 程序异常: 非法操作,地址越界,断点,除数为0
- 系统调用
中断处理过程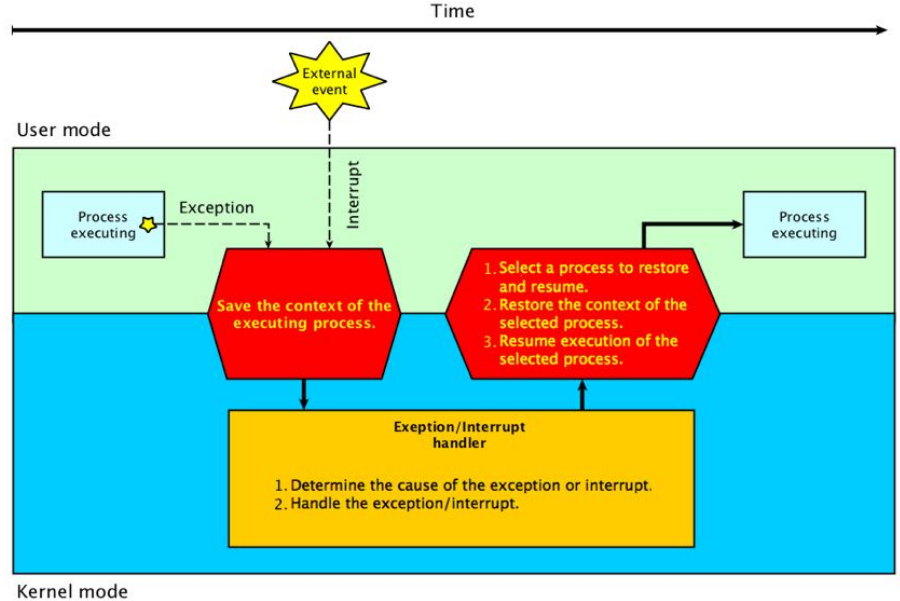
特权指令和非特权指令
- Privileged Instructions
- 只能在内核模式下运行的指令
- I/O指令和停止指令
- 关闭所有中断
- 设置定时器
- 进程切换
- 只能在内核模式下运行的指令
- Non-Privileged Instructions
- 只能在用户模式下运行的指令
模式切换
- 中断是用户态向核心态转换的唯一途径,系统调用实质上也是一种中断
- OS提供
Load PSW指令装载用户进程返回用户状态
进程切换
- 切换时机
- 进程需要进入等待状态(主动)
- 进程被抢占CPU而进入就绪状态(被动)
- 切换过程
- 保存被中断进程的上下文信息(Context)
- 修改被中断进程的控制信息(如状态等)
- 将被中断的进程加入相应的状态队列
- 调度一个新的进程并恢复它的上下文信息
进程调度
进程控制块
- A Process Control Block(PCB)contains many pieces of information associated with a specific process.(一个进程控制块(PCB)包含许多与特定进程相关的信息)

进程在物理内存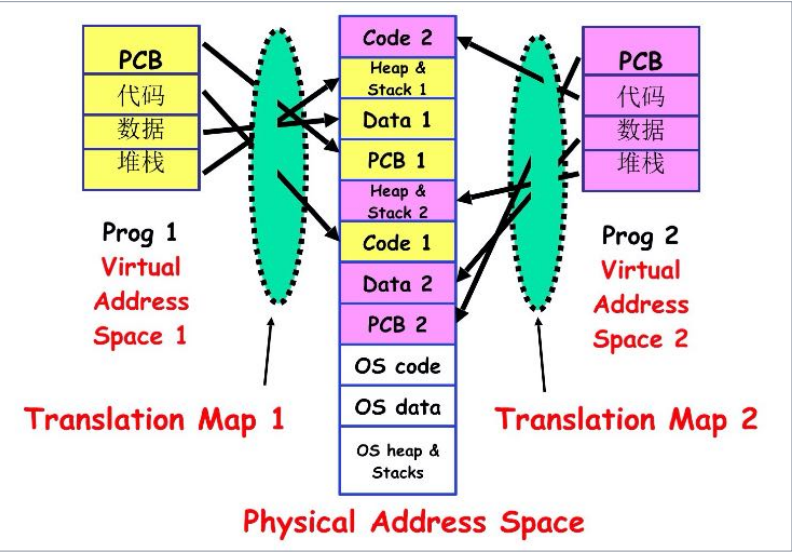
进程队列(PROCESS QUEUES)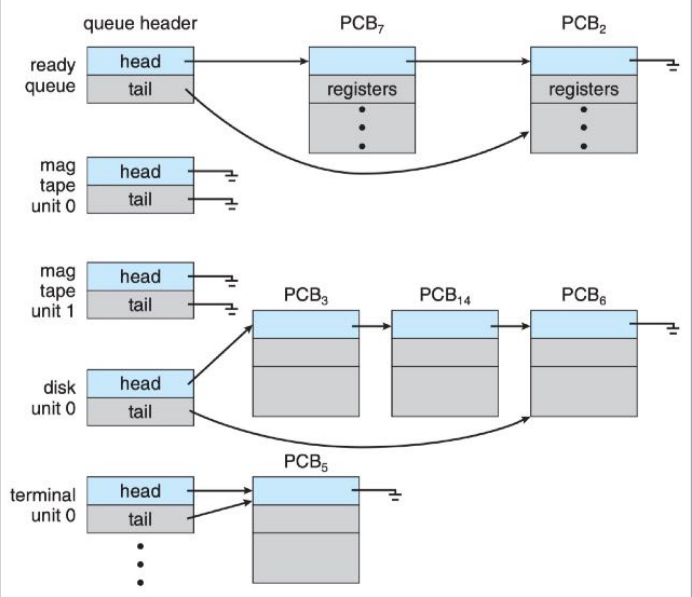
进程调度(PROCESS SCHEDULING)
进程在整个生命周期中会在各个调度队列中迁移,由操作系统的一个调度器(scheduler)来执行。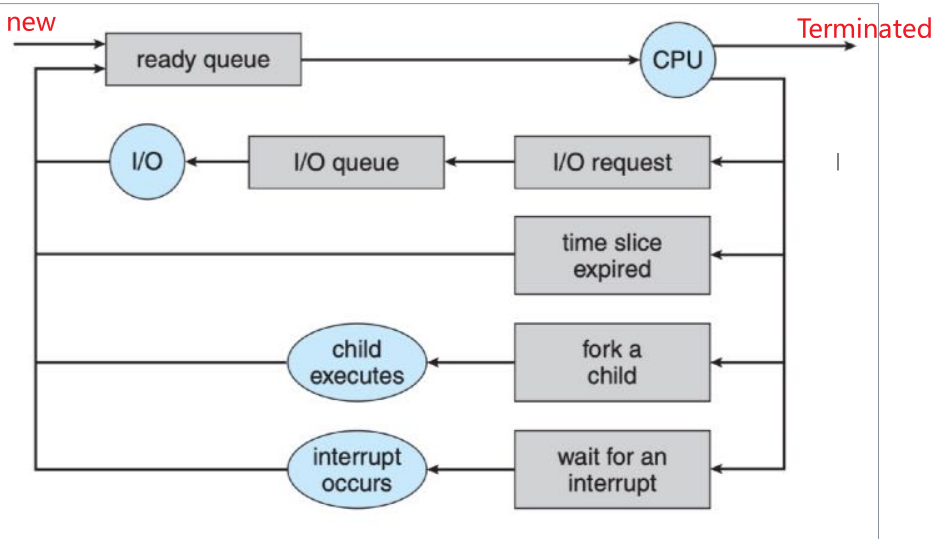
线程
进程定义
动机
- 一个应用通常需要同时处理很多工作,比如一个Web浏览器,可能需要同时处理文字和图片,这些同时执行的任务可称为“执行流”,我们不希望它们是顺序执行的。
- 早期,每个执行流都要创建一个进程来实现,但是进程的创建需要消耗大量的时间和资源。
- 现在,和一个应用相关的所有执行任务都装在一个进程里,这些进程内部的执行任务就是“线程”(Thread)。
采用多线程的优点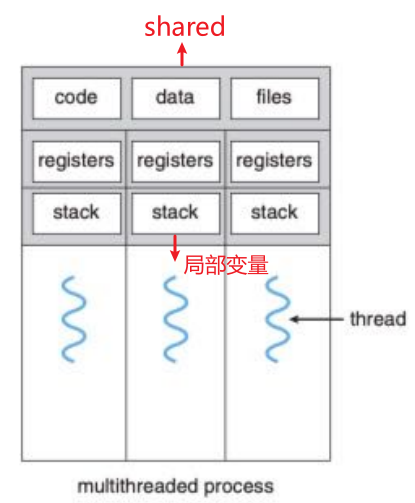
- 响应性
- 资源共享
- 经济
- 可伸缩性
DEFINITION OF THREAD
- 一个线程是CPU使用的基本单元,它包含一个
thread id,program counter,register set和stack - 它和同属于一个进程的其它线程共享它的代码部分,数据部分以及其它的操作系统资源,例如打开的文件和信号
- 一个传统的进程(heavyweight process)只有一个线程控制流,如果一个进程(lightweight process)有多个线程的控制流那么它可以在同一时刻执行多个任务
多线程模型
多核编程
在多处理器系统中,多核编程机制让应用程序可以
更有效地将自身的多个执行任务(并发的线程)分
散到不同的处理器上运行,以实现并行计算。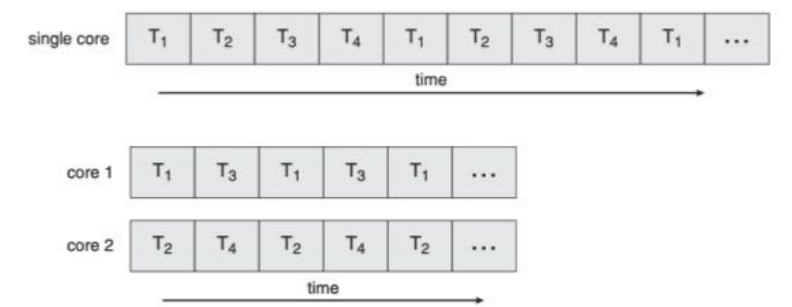
多线程模型
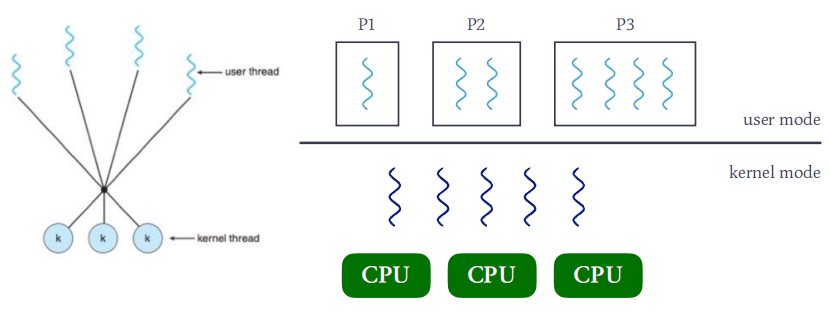
用户线程ULT(User Level Thread)
- ULT在user mode下运行,它的管理无需内核支持。
内核线程KLT(Kernel Level Thread)
- KLT在kernel mode下运行,由操作系统支持与管理。
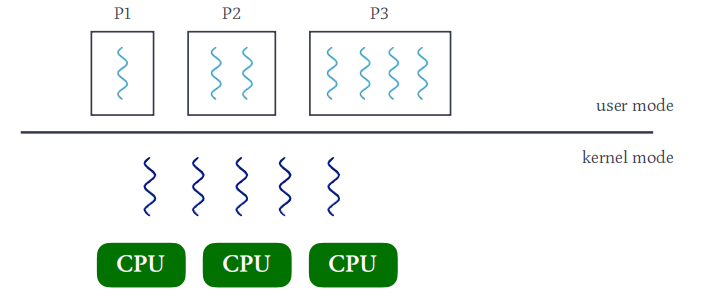
M:1模型
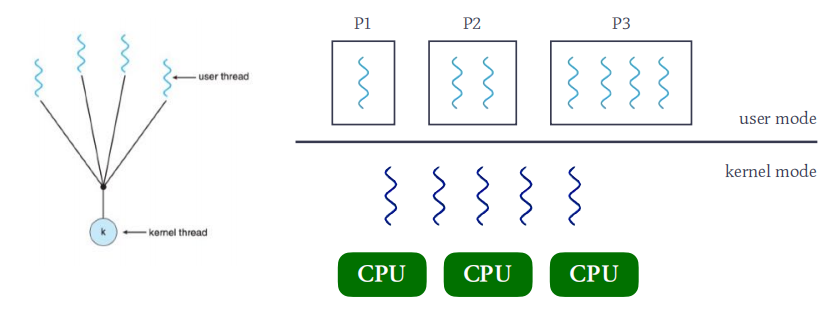
1:1模型
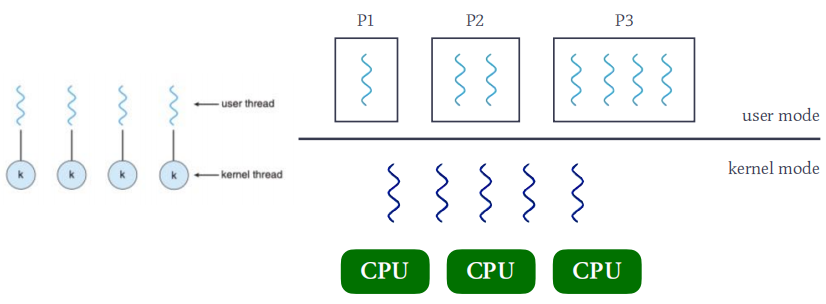
M:M模型
线程库
- Thread Library为程序员提供创建和管理线程的API
- POSIX Pthreads:用户线程库和内核线程库
- Windows Threads:内核线程库
- Java Threads:依据所依赖的操作系统而定
CPU调度
CPU调度程序
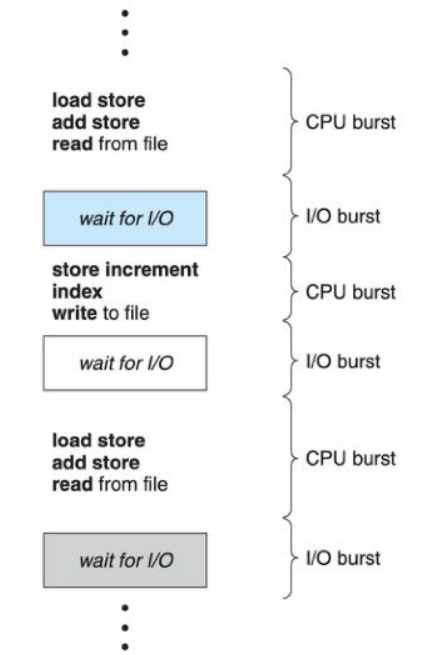
多道程序设计的目的将CPU的利用率最大化。
多个进程同时存在于内存(并发),当一个进程暂不使用CPU时,系统调度另一个进程占用CPU。
CPU-BURST DURATIONS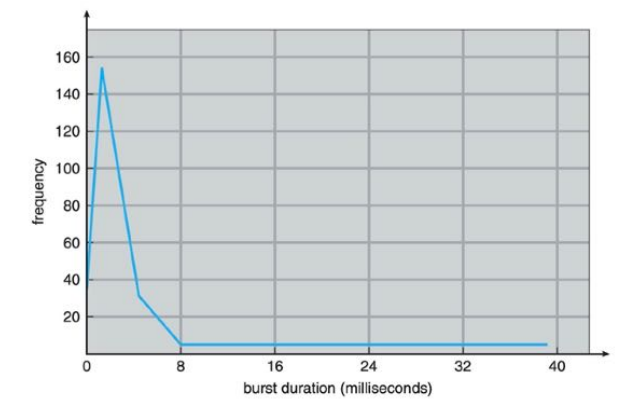
- CPU-bound program
- I/O-bound program
无论何时当CPU变得空闲时,操作系统必须在就绪队列中的进程中挑选一个执行,这个被选中的进程由 CPU scheduler选中并送出执行
抢占调度
- 非抢占调度(Nonpreemptive scheduling)
- 一旦某个进程得到CPU,就会一直占用到终止或等待状态。
- 抢占调度(Preemptive scheduling)
CPU调度准则
调度算法性能的衡量
- CPU利用率:CPU的忙碌程度
- 响应时间:从提交任务到第一次响应的时间
- 等待时间:进程累积在就绪队列中等待的时间
- 周转时间:从提交到完成的时间
- 呑吐率:每个时钟单位处理的任务数
- 公平性:以合理的方式让各个进程共享CPU
调度性能指标
- 作业(job)= 进程(process)
- 假设作业i提交给系统的时刻是$t_s$,完成的时刻是$t_f$,
所需运行时间为$t_k$,那么: - 平均作业周转时间 T ($t_i$是单个作业的周转时间)
$$
T =(\sum_{i = 1}^{n} t_i) \times \frac{1}{n} \qquad (t_i = t_f - t_s)
$$
调度算法
先来先服务(FCFS)
First-Come, First-Served (FCFS)
- 早期系统里,FCFS意味着一个程序会一直运行到结束(尽管其中会出现等待I/O的情况)
- 如今,当一个程序阻塞时会让出CPU
例题:
Process Time p1 28 p2 9 p3 3 如果三个进程的到达顺序是: P1 , P2 , P3
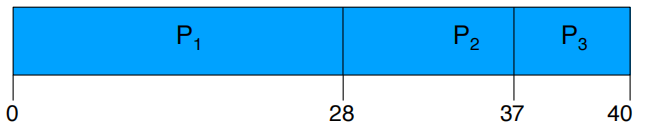
等待时间分别是: P1 = 0; P2 = 28; P3 = 37
平均等待时间是: (0 + 28 + 37)/3 = 22
平均作业周转时间是: (28 + 37 + 40)/3 = 35
如果换一种执行顺序的话: P3 , P2 , P1
等待时间分别是: P1 = 12; P2 = 3; P3 = 0
平均等待时间是: (12 + 3 + 0)/3 = 5
平均周转时间是: (3 + 12 + 40)/3 = 18
第二种排列方式比第一种要好,平均周转时间缩短为18
FCFS的优缺点
- 简单易行(+)
- 如果短作业处在长作业的后面将导致周围时间变长。
时间片轮转(ROUND ROBIN)
- 每个进程都可以得到相同的CPU时间(CPU时间片, time slice),当时间片到达,进程将被剥夺CPU并加入就绪队列的尾部 。
- 抢占式调度算法
- n个就绪队列中的进程和时间片q =>
- 每个进程获得1/n的CPU时间,大约是q个时间单位
- 没有进程等待时间会超过 (n-1)q
例题(时间片=20)
| Process | CPU Time |
|---|---|
| P1 | 68 |
| P2 | 53 |
| P3 | 24 |
| P4 | 8 |

等待时间分别是:
- P1=(68-20)+(112-88)+(145-132)=85
- P2=(20-0)+(88-40)+(132-108)=92
- P3=(40-0)+(108-60)=88
- P4=(60-0)=60
- 平均等待时间 = (85+92+88+60)/4=81.25
- 平均周转时间 = (153+145+112+68)/4=119.5
RR算法分析
- 时间片(time slice)取选
- 取值太小:进程切换开销显著增大(不能小于进程切换的时间)
- 取值较大:响应速度下降(取值无穷大将退化成FCFS)
- 一般时间片的选取范围为 10ms~100ms
- 上下文切换的时间大概为 0.1ms~1ms (1%的CPU时间开销)
- RR算法优缺点
- 公平算法(+)
- 对长作业带来额外的切换开销(-)
最短作业优先(SJF)
- SJF(Shortest Job First):下一次调度总是选择所需要
CPU时间最短的那个作业(进程) - 这是一个非抢占式算法,也可以改成抢占式SRTF。
SJF/SRTF算法分析
- 该算法总是将短进程移到长进程之前执行,因此平均等待时间
最小,该算法被证明是最优的。 - 饥饿现象:长进程可能长时间无法获得CPU
- 预测技术
- 该算法需要事先知道进程所需的CPU时间
- 预测一个进程的CPU时间并非易事
- 优缺点:
- 优化了响应时间(+)
- 难以预测作业CPU时间(-)
- 不公平算法(-)
优先级调度(PRIORITY)
优先级通常为固定区间的数字,如[0, 10]:
- 数字大小与优先级高低的关系在不同系统中实现不一样,以 Linux 为例,0为最高优先级。
- 调度策略:下一次调度总是选择优先级最高的进程。
- SJF是优先级调度的一个特例。
- 优先级调度可以是抢占式,也可以是非抢占式。
优先级定义
- 静态优先级
- 优先级保持不变,但会出现不公平(饥饿)现象
- 动态优先级(退化Aging)
- 根据进程占用CPU时间:当进程占有CPU时间愈长,则慢慢降低它的优先级;
- 根据进程等待CPU时间:当进程在就绪队列中等待时间愈长,则慢慢提升它的优先级
Linux线程调度
1. scope
- PTHREAD_SCOPE_SYSTEM, 系统, SCS (linux支持)
- PTHREAD_SCOPE_PROCESS, 进程, PCS
2. thread attribution of scheduling
- policy
- Normal Scheduling:
SCHED_OTHER,SCHED_IDLE,SCHED_BATCH(Priority value = 0) - Real-Time:
SCHED_FIFO,SCHED_RR(Priority value = [1, 99])
- Normal Scheduling:
ps -eLf: 观察多线程的tid的数量SCHED_OTHER: time-sharing policy(RR)NICE: [-20, 19]PR= 20 + NICE (PR值越小,优先级越高)
top -p pid: 显示进程p的信息real-timePR= -1 - Priority value [-100, -2]
chrt -p pid: 观察进程调度策略以及它的Priority valuesudo chrt -f(FIFO) / -r(RR) + -p + (priority value) + pid: 将pid进程切换为real-time,并设置其priority value值和policy
3. 调度策略的过程
- Normal
SCHED_OTHER(抢占式)- 分时调度(CFS)
- 动态优先级(NICE)
real-time(抢占式)SCHED_FIFO(PR值相同时)SCHED_RR(PR值相同时)
Synchronization
并发进程/线程
- 在内存中同时存在的若干个进程/线程,由操作系统的调度程序采用适当的策略将他(们)调度至CPU(s)上运行,同时维护他们的状态队列。
- 多个并发进程/线程从宏观上是同时在运行;
- 从微观上看,他们的运行过程是走走停停;
- 并发的进程/线程之间是交替执行(Interleaving)。
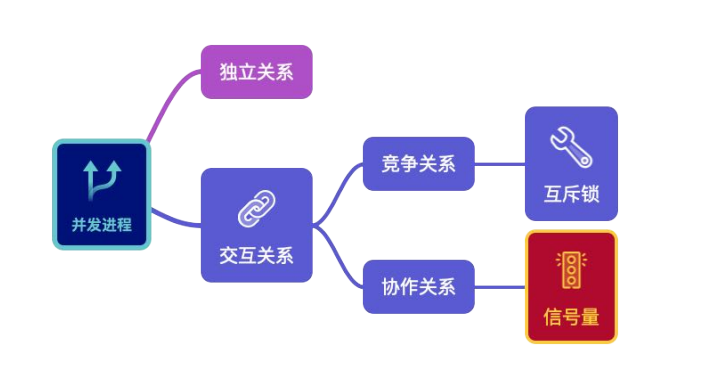
并发进程之间的关系
- 独立关系
- 并发进程分别在自己的变量集合上运行
- 例如:chrome进程和music进程
- 交互关系
- 并发进程执行过程中需要共享或是交换数据
- 例如:银行交易服务器上的receiver进程和handler进程
- 交互的并发进程之间又存在着竞争和协作的关系
异步
- Asynchronous means RANDOM!
- 会引发竞争条件(Race Condition):一种这样的情况:多个进程并发操作同一个数据导致执行结果依赖于特定的进程执行顺序。
同步
Process Synchronization means a mechanism to maintain the consistency of data shared in cooperative processes.
Synchronization Tool Kits
- Mutex lock
- Semaphore
Mutex Locks
临界区问题(CRITICAL-SECTION PROBLEM)
- 每个并发进程都有一段代码称为临界区, 在临界区中的进程可能会改变共享的变量,更新表格,写入文件等等
- 当一个进程在临界区执行时,其他进程不允许在临界区中执行
- 临界区问题是设计一个进程可以用来合作的协议
进程进出临界区协议
1 | do{ |
- 进入临界区前在entry section
要请求许可; - 离开临界区后在exit section
要归还许可。
临界区管理准则
- Mutual exclusion (Mutex):互斥
- Progress:前进
- Bounded waiting:有限等待
有空让进
择一而入
无空等待
有限等待
让权等待
金鱼生存法则
- 每天喂一次,且仅一次
- 今天一人喂过,另一人就不能再喂
- 今天一人没有喂过,另一人就必须喂
1
2
3
4
5
6
7
8
9Alice
leave noteAlice
while(noteTom){
do nothing
}
if (no feed){
feed fish
}
remove noteAlice软件解决临界区管理1
2
3
4
5
6
7
8Tom
leave noteTom
if (no NoteAlice){
if (no feed){
feed fish
}
}
remove noteTom - 实现需要较高的编程技巧
- 两个进程的实现代码是不对称的,当处理超过2个进
程的时候,代码的复杂度会变得更大 - 两个著名的软件方案
- Peterson
- Dekker
互斥锁
MUTEX LOCKS
- 操作系统设计者开发软件工具来解决临界区问题。这些工具中最简单的是互斥锁。
- 一个进程在进入临界区前必须获得锁
- 当它退出临界区时必须释放这个锁
锁的基本操作
- 上锁
- 等待锁至打开状态
- 获得锁并锁上
- 解锁
- 原子操作
原子操作
- 原子操作意味着这个操作在运行时不能被中断
- 原子操作(原语)是操作系统重要的组成部分,下
面2条硬件指令都是原子操作,它们可以被用来实现
对临界区的管理(也就是“锁”)。- test_and_set()
- compare_and_swap()
锁的实现
1 | bool ts(bool* target){ |
忙式等待(BUSY WAITING)
- 忙式等待是指占用CPU执行空循环实现等待
- 这种类型的互斥锁也被称为“自旋锁”(spin lock)
- 缺点:浪费CPU周期,可以将进程插入等待队列以让出CPU
的使用权; - 优点:进程在等待时没有上下文切换,对于使用锁时间不
长的进程,自旋锁还是可以接受的;在多处理器系统中,
自旋锁的优势更加明显。
- 缺点:浪费CPU周期,可以将进程插入等待队列以让出CPU
Semaphores
信号量与PV操作
信号量
- 信号量(Semaphore)是一种比互斥锁更强大的同步
工具,它可以提供更高级的方法来同步并发进程。- 1965年由荷兰学者Dijkstra提出
- 一个信号量就是一个整数,除了初始化之外它只能被两个标准的原子操作访问
- P: wait() operation
- V: signal() operation
- P V操作必须成对出现
信号量的实现
1 | P(s){ |
信号量的使用
BINARY SEMAPHORE
- 二值信号量的值只能是0或1,通常将其
初始化为1,用于实现互斥锁的功能。
1 | semaphore mutex = 1; |
COUNTING SEMAPHORE
- 一般信号量的取值可以是任意数值,用于控制并发
进程对共享资源的访问。
1 | semaphore road = 2; |
信号量实现同步
同步问题
- 同步问题实质是将异步的并发进程按照某种顺序执行;
- 解决同步的本质就是要找到并发进程的交互点,利用P操作的等待特点来调节进程的执行速度;
- 通常初始值为0的信号量可以让进程直接进行等待状态,直到另一个进程唤醒他。
经典同步问题
生产-消费者问题
生产者(P)与消费者(C)共用一个缓冲区,生产者不能往“满”的缓冲区中放产品,消费者不能从“空”的缓冲区中取产品。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23//单缓冲解决方案
Semaphore empty = 1; //signal for producer
Semaphore full = 0; //signal for consumer
Producer {
while (true) {
//make a product;
P(empty);
put the product into buffer;
V(full);
}
}
Consumer {
while (true) {
P(full);
pick product from buffer;
V(empty);
//consume the product;
}
}
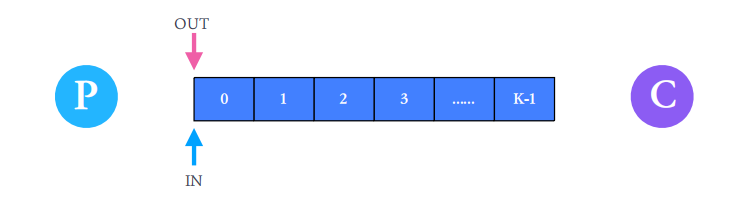
THE BOUNDED-BUFFER PROBLEM
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
void printBank();
sem_t empty;
sem_t full;
int Bank[10] = {0};
int in = 0, out = 0;
pthread_mutex_t lock = PTHREAD_MUTEX_INITIALIZER;
void* producerThd(void* arg)
{
for(int i = 0; i < 20; i++)
{
sem_wait(&empty);
pthread_mutex_lock(&lock);
Bank[in] = 1;
in = (in + 1) % 10;
printBank();
sleep(0.1);
pthread_mutex_unlock(&lock);
sem_post(&full);
}
pthread_exit(0);
}
void* consumerThd(void* arg)
{
for(int i = 0; i < 20; i++)
{
sem_wait(&full);
pthread_mutex_lock(&lock);
Bank[out] = 0;
out = (out + 1) % 10;
printBank();
sleep(1);
pthread_mutex_unlock(&lock);
sem_post(&empty);
}
pthread_exit(0);
}
void printBank()
{
printf("Bank:");
for(int i = 0; i < 10; i++)
{
printf("[%d]", Bank[i]);
if(i == 9) puts("");
}
}
int main()
{
pthread_t producer_tid, consumer_tid;
sem_init(&empty, 0, 10);
sem_init(&full,0 , 0);
pthread_create(&producer_tid, NULL, producerThd, NULL);
pthread_create(&consumer_tid, NULL, consumerThd, NULL);
pthread_join(producer_tid, NULL);
pthread_join(consumer_tid, NULL);
sem_destroy(&empty);
sem_destroy(&full);
return 0;
}苹果桔子问题
- 问题描述
- 桌上有一只盘子,每次只能放入一只水果
- 爸爸专向盘子中放苹果,妈妈专向盘子中放桔子
- 儿子专等吃盘子中的桔子,女儿专等吃盘子里的苹果
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
sem_t empty;
sem_t apple;
sem_t orange;
pthread_mutex_t work_mutex = PTHREAD_MUTEX_INITIALIZER;
int fruitCount = 0;
void* procf(void* arg)
{
while(1)
{
sem_wait(&empty);
pthread_mutex_lock(&work_mutex);
printf("爸爸放入一个苹果(盘子当前水果数量:%d) \n", ++fruitCount);
pthread_mutex_unlock(&work_mutex);
sem_post(&apple);
sleep(0.1);
}
pthread_exit(0);
}
void* procm(void* arg)
{
while(1)
{
sem_wait(&empty);
pthread_mutex_lock(&work_mutex);
printf("妈妈放入一个橙子(盘子当前水果数量:%d) \n", ++fruitCount);
pthread_mutex_unlock(&work_mutex);
sem_post(&orange);
sleep(0.2);
}
pthread_exit(0);
}
void* procs(void* arg)
{
while(1)
{
sem_wait(&apple);
pthread_mutex_lock(&work_mutex);
printf("儿子吃掉一个苹果(盘子当前水果数量:%d) \n", --fruitCount);
pthread_mutex_unlock(&work_mutex);
sem_post(&empty);
sleep(0.2);
}
pthread_exit(0);
}
void* procd(void* arg)
{
while(1)
{
sem_wait(&orange);
pthread_mutex_lock(&work_mutex);
printf("女儿吃掉一个橙子(盘子当前水果数量:%d) \n", --fruitCount);
pthread_mutex_unlock(&work_mutex);
sem_post(&empty);
sleep(0.2);
}
pthread_exit(0);
}
int main()
{
pthread_t father;
pthread_t mother;
pthread_t son;
pthread_t daughter;
sem_init(&empty, 0, 3);
sem_init(&apple, 0, 0);
sem_init(&orange, 0, 0);
pthread_create(&father, NULL, procf, NULL);
pthread_create(&mother, NULL, procm, NULL);
pthread_create(&son, NULL, procs, NULL);
pthread_create(&daughter, NULL, procd, NULL);
sleep(1);
sem_destroy(&empty);
sem_destroy(&apple);
sem_destroy(&orange);
return 0;
}- 问题描述
死锁
死锁的特征
哲学家用餐死锁问题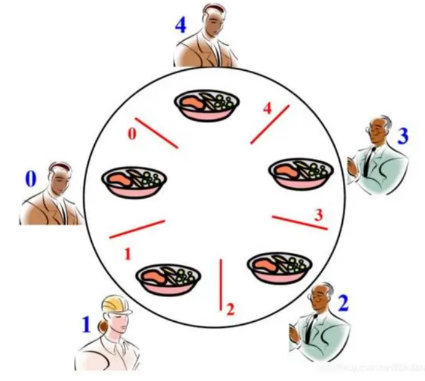
- 当所有人同时拿到一侧的筷子时,发生永远等待现象(即死锁)。
- 有若种办法可避免死锁:
- 至多允许四个哲学家同时吃;
- 奇数号先取左手边的筷子,偶数号先取右手边的筷子;
- 每个哲学家取到手边的两根筷子才吃,否则一根也不取。
- 进程访问资源流程:申请 ➠ 使用 ➠ 释放
DEADLOCK
- In a multiprogramming environment, several processes may compete for a finite number of resources.
- A process requests resources; if the resources are not available at that time, the process enters a waiting state.
- Sometimes, a waiting process is never again able to change state, because the resources it has requested are held by other waiting processes.
- This situation is called a deadlock
死锁与饥饿
- 饥饿:进程长时间的等待
- e.g.低优先级进程总是等待高优先级所占有的进程
- 死锁:循环等待资源
- A和B分别占有打印机和扫描仪
- 同时分别申请扫描仪和打印机
- 死锁 -> 饥饿 (反之不亦然)
- 饥饿可能终止
- 如果无外部干涉,死锁无法终止
产生死锁的四个必要条件
- 互斥使用
- 一个时刻,一个资源仅能被一个进程占有
- 不可剥夺
- 除了资源占有进程主动释放资源,其它进程都不可抢夺其资源
- 占有和等待
- 一个进程请求资源得不到满足等待时,不释放已占有资源
- 循环等待(上面三个条件同时存在产生的结果)
- 每一个进程分别等待它前一个进程所占有的资源
死锁的解决方案
- 死锁的防止 (Prevention)
- 破坏四个必要条件之一
- 死锁的避免 (Avoidance)
- 允许四个必要条件同时存在,在并发进程中做出妥善安 排避免死锁的发生
- 死锁的检测和恢复 (Detection)
- 允许死锁的发生,系统及时地检测死锁并解除它
死锁的防止
破坏死锁任一必要条件
- 互斥使用
- 不可剥夺
- 占有和等待
- 循环等待
死锁的避免
安全状态(SAFE STATE)
- A state is safe if the system can allocate resources to each process (up to its maximum) in some order and still avoid a deadlock. More formally, a system is in a safe state only if there exists a safe sequence.
- If no such sequence exists, then the system state is said to be unsafe.
- A safe state is NOT a deadlocked state.
- An unsafe state MAY lead to a deadlock
死锁的避免
系统对进程的每一次资源申请都进行详细的计算,
根据结果决定是分配资源还是让其等待,确保系统
始终处于安全状态,避免死锁的发生。银行家算法(Banker’s algorithm)
- 已知系统中所有资源的种类和数量
- 已知进程所需要的各类资源最大需求量
- 该算法可以计算出当前的系统状态是否安全(寻找安全序列)
银行家算法
Available: 当前系统中可用资源数量
Max: 每个进程的最大资源需求量
Allocation: 已经分配给进程的资源数量
Need: 每个进程还需要的资源数量
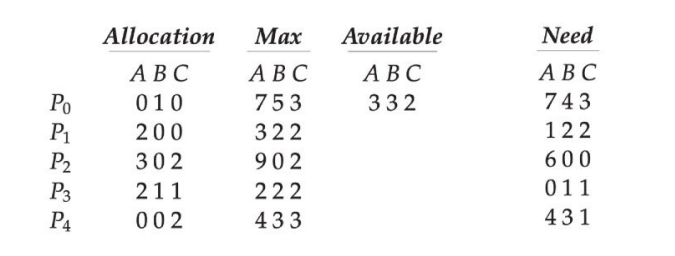
存在安全序列{ P1,P3,P4,P2,P0 },系统处于安全状态
银行家算法的优缺点
- 优点:允许死锁必要条件同时存在
- 缺点:缺乏实用价值
- 进程运行前就要求知道其所需资源的最大数量
- 要求进程是无关的,若考虑同步情况,可能会打乱安全序列
- 要求进入系统的进程个数和资源数固定
死锁的检测
死锁的检测与恢复
- 允许死锁发生,操作系统不断监视系统进展情况,
判断死锁是否发生 - 一旦死锁发生则采取专门的措施,解除死锁并以最
小的代价恢复操作系统运行 - 死锁检测的时机
- 当进程等待时检测死锁(系统开销大)
- 定时检测
- 系统资源利用率下降时检测死锁
资源分配图表示法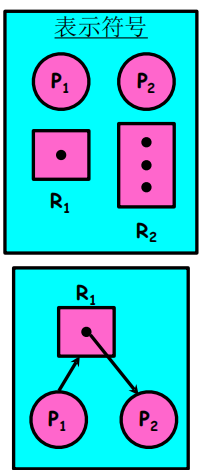
- 资源类(资源的不同类型)
- 资源实例(存在于每个资源中)
- 进程
- 申请边
- 分配边
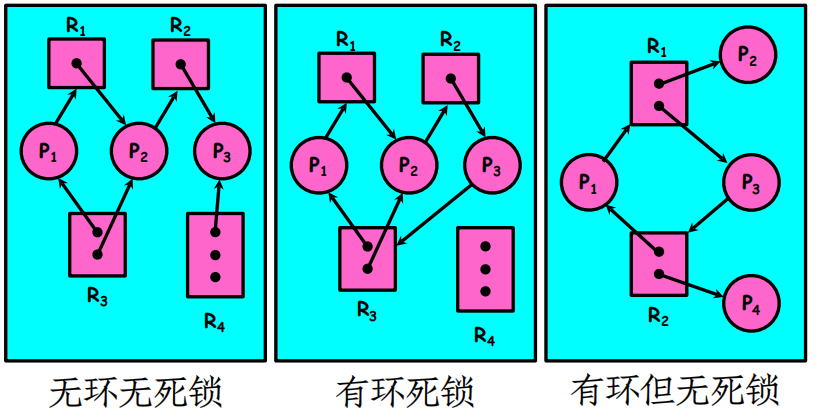
死锁定理
- 如果能在“资源分配图”中消去某进程的所有请求边和分配边,则称该进程为孤立结点。
- 可完全简化
- 不可完全简化
- 系统为死锁状态的充分条件是:当且仅当该状态的
“进程―资源分配图”是不可完全简化的。该充分
条件称为死锁定理
死锁的解除
- 中止进程,强制回收资源
- 交通问题:将某列火车吊起来
- 哲学家问题:将某个哲学家射死
- 剥夺资源,但不中止进程
- 进程回退(roll back)
- 就像DVD的回退,好像最近一段时间什么都没有发生过
- 交通问题:让某列火车倒车
- 哲学家问题:让某个哲学家放下一把叉子
- 重新启动
- 没有办法的办法,但却是一个肯定有效的办法
HOW OS DO TO DEADLOCKS?
In the absence of algorithms to detect and recover from deadlocks, we may arrive at a situation in which the system is in a deadlocked state yet has no way of recognizing what has happened. In this case, the undetected deadlock will cause the system’s performance to deteriorate, because resources are being held by processes that cannot run and because more and more processes, as they make requests for resources, will enter a deadlocked state. Eventually, the system will stop functioning and will need to be restarted manually.
Although this method may not seem to be a viable approach to the deadlock problem, it is nevertheless used in most operating systems.
内存管理
内存管理目标
MAIN MEMORY
- Main memory is central to the operation of a modern computer system.
- Memory consists of a large array of bytes, each with its own address.
- The CPU fetches instructions from memory according to the value of the program counter(PC). These instructions may cause additional loading from and storing to specific memory addresses.
- A typical instruction-execution cycle, for example, first fetches an instruction from memory. The instruction is then decoded and may cause operands to be fetched from memory. After the instruction has been executed on the operands, results may be stored back in memory.
高速缓存CACHE
- 高速缓存是一种存取速度比内存快,但容量比内存
小的多的存储器,它可以加快访问物理内存的相对
速度。
保护操作系统和用户进程
- 用户进程不可以访问操作系统内存数据,以及用户进程空间之间不能互相影响
- 通过硬件实现,因为操作系统一般不干预CPU对内存的
访问- base register:基址寄存器
- limit register:限长寄存器
- 上述两个寄存器的值只能被操作系统的特权指令加载
- 通过硬件实现,因为操作系统一般不干预CPU对内存的
内存管理目标
- 存取速度
- 操作正确(分配和回收)
- 保护操作系统
- 保护用户进程
- 地址转换
逻辑地址和物理地址
地址空间和地址转换
- 逻辑地址:面向程序的地址,总是从0开始编址,每一条指令的逻辑地址就是与第1条指令之间的相对偏移,因此逻辑地址也叫相对地址或虚拟地址。
- 物理地址:内存单元看到的实际地址,也称为绝对地址。
- 所有逻辑地址的集合称为逻辑地址空间,这些逻辑地址对应的所有物理地址集合称为物理地址空间。
- 地址转换:由逻辑地址转换成物理地址。
内存管理单元MMU
- Memory-Management Unit完成逻辑地址到物理地址运行时的转换工作。
- 重定位寄存器(relocation register)或基址寄存器
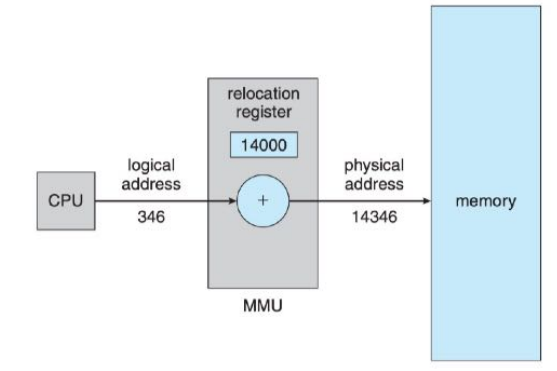
连续内存分配
CONTIGUOUS MEMORY ALLOCATION
- 在连续内存分配中,每个进程都包含在单个内存段中,该内存段与包含下一个进程的内存段相邻。
- Memory allocation
- Memory recycle
- Memory protection
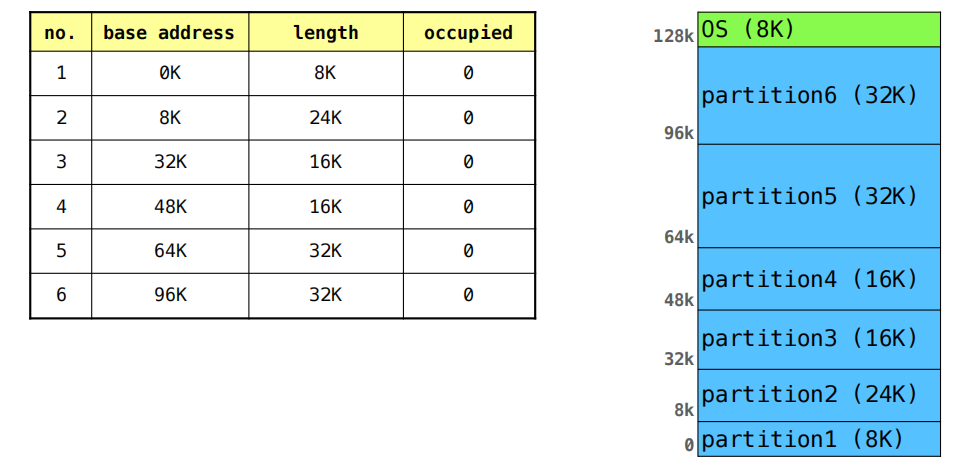
FIXED-SIZED PARTITION
- 内存被划分为几个固定大小的分区,每个分区只能包含一个进程。
VARIABLE-PARTITION
- 在可变分区方案中,操作系统保存两个表,表明哪些部分的内存是可用的,哪些部分的内存是占用的。
- 最初,所有内存都可用于用户进程,并被认为是一个大块的可用内存,一个孔/洞。
- 最终,正如你将看到的,内存包含一组不同大小孔/洞的集合
HOLES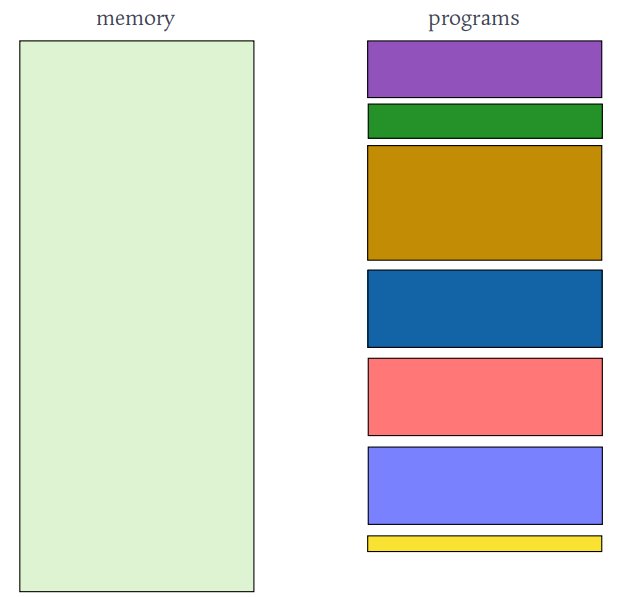
动态存储分配问题
- 首次适应
- 分配首个足够大的孔,效率最高
- 最佳适应
- 分配最小的足够大的孔,浪费最小
- 最坏适应
- 分配最大的孔,产生的剩余孔更可能被再利用
地址转换与保护
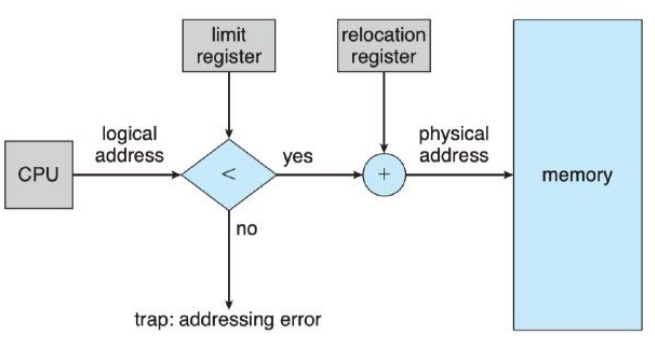
- 两种连续分配方案的地址转换方式是相似的:
- 物理地址 = 基址 + 逻辑地址
- 地址保护策略:与限长limit进行比较
碎片
- Fragmentation: some little pieces of memory hardly to be used.
- internal fragmentation
- external fragmentation
- compaction
- static relocation
- cost
- compaction
分段 & 分页
动机
- Solution to fragmentation: permit the logical address space of processes to be noncontiguous.
- The view of memory is different between
- logical (programmer’s ): a variable-sized segments
- physical : a linear array of bytes
- The hardware could provide a memory mechanism that mapped the logical view to the actual physical memory.
分段
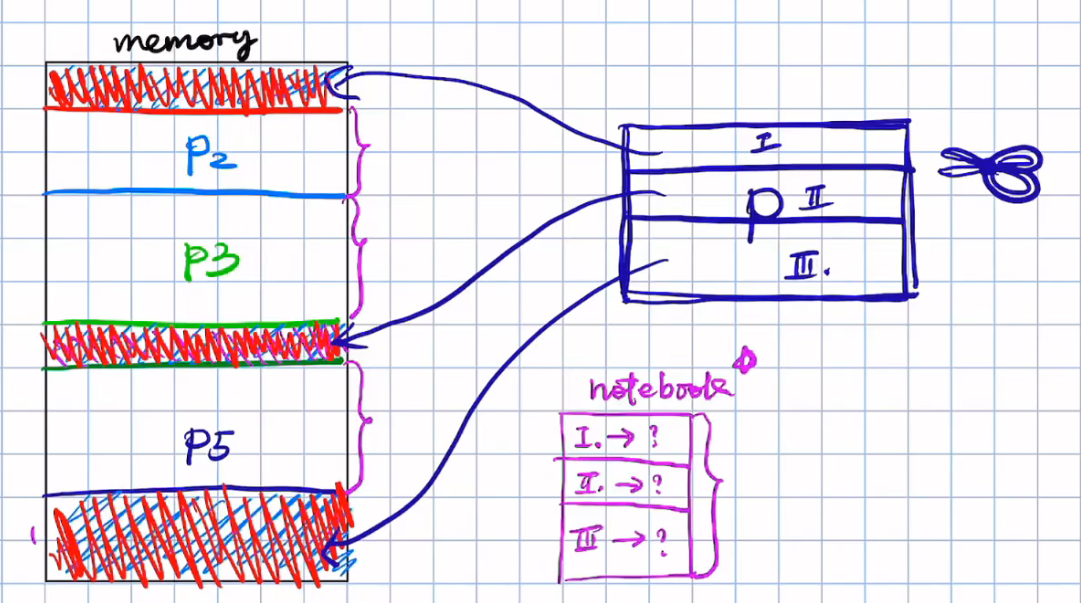
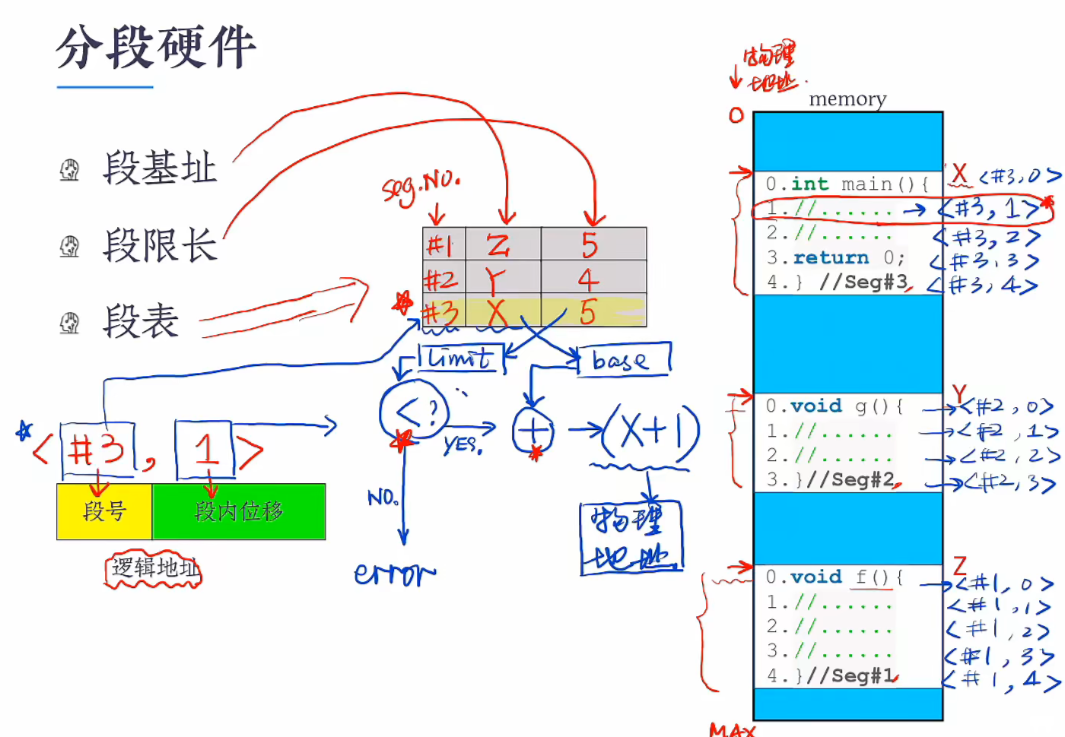
在分段机制下逻辑地址由 <段号,段内位移>组成,其次为了让逻辑地址映射到物理地址,OS需要维护一张表, 表里记录三个信息:1. 段号,2.段内基地址,3.限长
分页
基本方法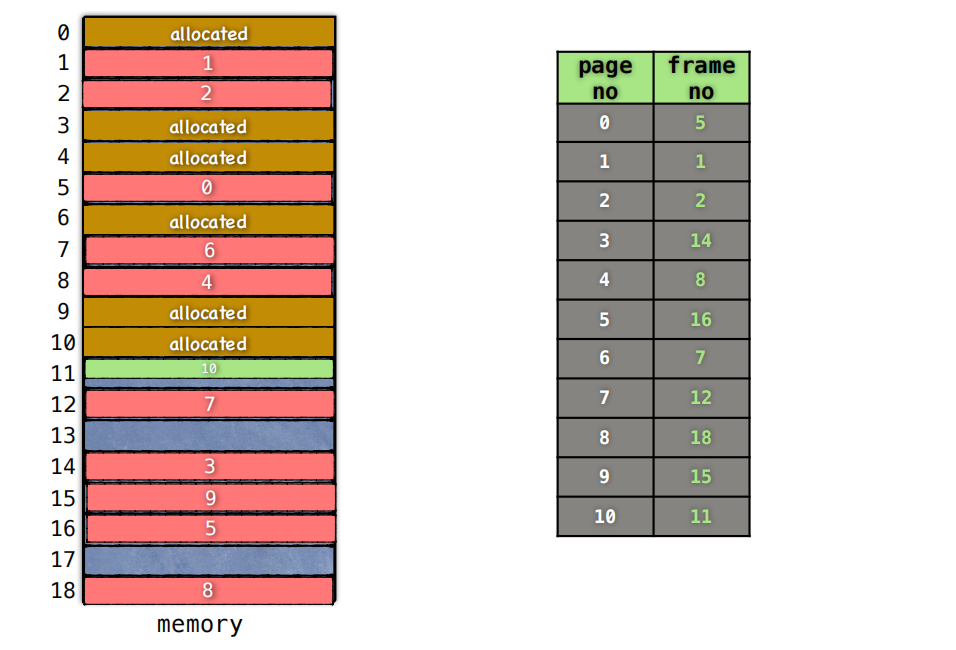

分页硬件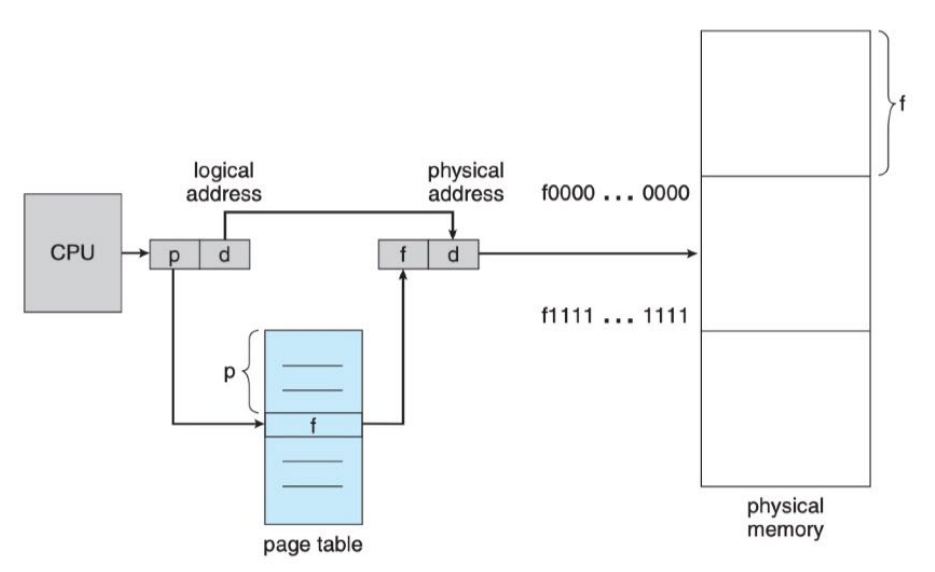
LOGICAL ADDRESS
- The page size (like the frame size) is defined by the hardware. The size of a page is a power of 2, varying between 512 bytes and 1 GB per page, depending on the computer architecture.
- The selection of a power of 2 as a page size makes the translation of a logical address into a page number and page offset particularly easy.
- If the size of the logical address space is $2^m$ , and a page size is $2^n$bytes, then the high-order $m − n$ bits of a logical address designate the page number, and the n low-order bits designate the page offset. Thus, the logical address is as follows:
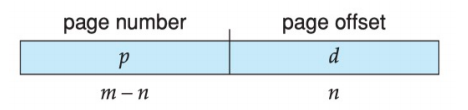
分段与分页的区别
| 分段 | 分页 |
|---|---|
| 信息的逻辑单位 | 信息的物理单位 |
| 段长是任意的 | 页长由系统确定 |
| 段的起始地址可以从主存任一地址开始 | 页框起始地址只能以页框大小的整数倍开始 |
| (段号,段内位移)构成了二维地址空间 | (页号,页内位移)构成了一维地址空间 |
| 会产生外部碎片 | 消除了外部碎片,但会出现内部碎片 |
页表
页面大小
- 若逻辑地址长度为m bits,页面大小:$2^n$ Bytes
- 页内位移占n bits
- 页号占$m-n$ bits
PAGE TABLE
- The operating system maintains a copy of the page table for each process.
- This copy is used to translate logical addresses to physical addresses.
- It is also used by the CPU dispatcher to define the hardware page table when a process is to be allocated the CPU.
- Paging therefore increases the context-switch time.
快表
HARDWARE PAGE TABLE
- The page table is kept in main memory, and a page-table base register (PTBR) points to the page table.
- Changing page tables requires changing only this one register, substantially reducing context-switch time.
- With this scheme, two memory accesses are needed to access a byte (one for the page-table entry, one for the byte)
TLB
- TLB(Translation Look-aside Buffer) is a kind of small, fast-lookup hardware cache. It is used with page tables in the following way.
- The TLB contains only a few of the page-table entries.
- When a logical address is generated by the CPU, its page number is presented to the TLB.
- If the page number is found, its frame number is immediately available and is used to access memory.
- If TLB miss, a memory reference to the page table must be made
PAGING WITH TABLE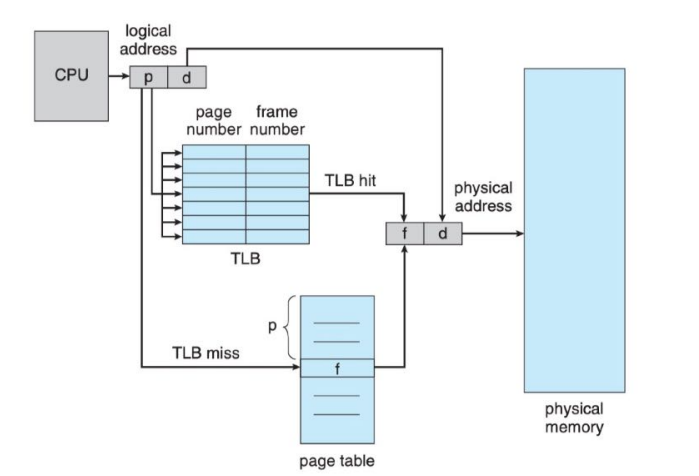
TLB HIT RATIO
- The percentage of times that the page number of interest is found in the TLB is called the hit ratio.
- An 80-percent hit ratio, for example, means that we find the desired page number in the TLB 80 percent of the time. If it takes 100 nanoseconds to access memory, please find the effective memory-access time.
- effective access time = 0.80 × 100 + 0.20 × 200 = 120 ns
基于页的保护与共享
保护
- 为了防止地址转换时出现异常,可在页表每个条目设置一个
valid-invalid比特位,用于表示该页的有效性。 - 这个方法可以被轻松扩展以提供更好的保护级别,如“只读”、“读写”、“可执行”等。
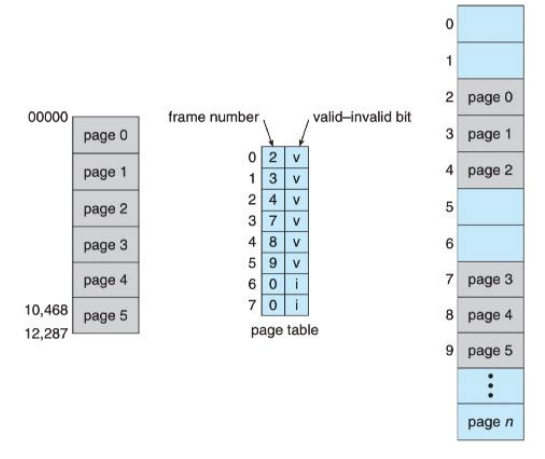
共享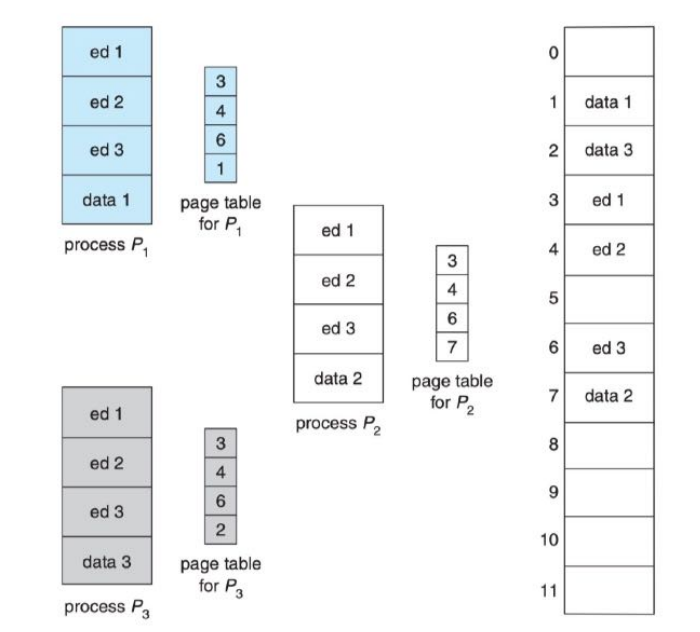
多级页表
页表大小
- 假设CPU是32bits,采用的逻辑地址是32bits,那么进程的逻辑地址空间大小为$2^{32}$Bytes,即4G Bytes。
- 若页面大小是4K Bytes,则一个进程最多被分成1M个页面,也就是说进程的页表最多有1M个页表项
- 若每个页表项占用4Bytes,则每个页表最多占用4MBytes空间(1K个连续页框)。
- 如何解决“连续”的困扰?
页表表
多级页表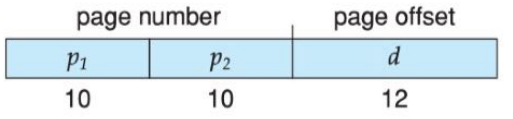
上面是一个32位地址采用两级页表的例子,页面大小是4KBytes,第一级页表页的数量是1K个,每个页表页中包含的页面数量也是1K个
下面是
x86-64架构CPU采用的四级页表方案:
Virtual Memory
局部性原理
- 时间局部性(Temporal locality)
- 如果某个信息这次被访问,那它有可能在不久的未来被多次访问。
- 空间局部性(Spatial locality)
- 如果某个位置的信息被访问,那和它相邻的信息也很有可能被访问到。
- 内存局部性(Memory locality)
- 访问内存时,大概率会访问连续的块,而不是单一的内存地址,其实就是空间局部性在内存上的体现。
- 分支局部性(Branch locality)
- 计算机中大部分指令是顺序执行,顺序执行和非顺序执行的比例大致是5:1。
- 等距局部性(Equidistant locality)
- 等距局部性是指如果某个位置被访问,那和它相邻等距离的连续地址极有可能会被访问到。
缓存CACHE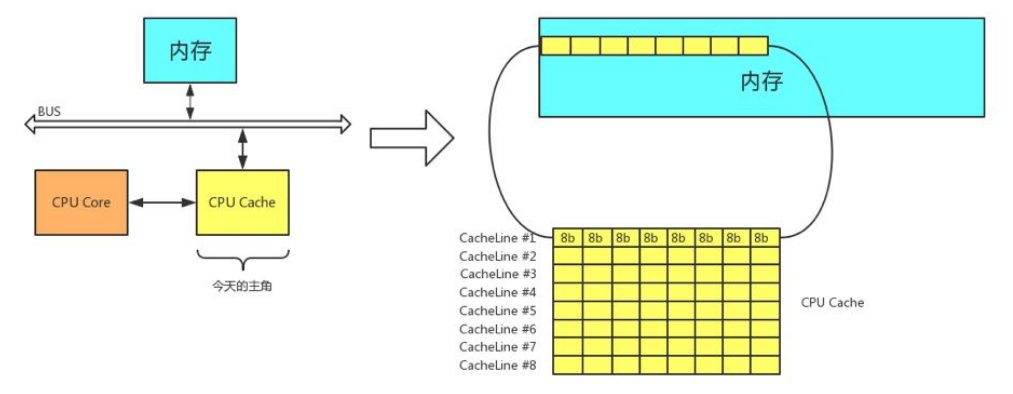
修改缓存数据
Write through- 修改缓存数据的同时修改内存数据
Write back- 只修改缓存数据,直到该数据要被清除出缓存再修改内存中的数据
虚拟内存
- 虚拟内存是一种允许执行不完全在内存中的进程的技术。
- 这种方案的一个主要优点是程序可以大于物理内存。
- 虚拟内存将主存抽象成一个极其庞大、统一的存储阵列,将用户所看到的逻辑内存与物理内存分开。
- 这种技术使程序员从内存存储限制的担忧中解脱出来。
部分装入和部分对换
- 部分装入
- 进程运行时仅加载部分进入内存,而不必全部装入, 其余部分暂时放在
swap space
- 进程运行时仅加载部分进入内存,而不必全部装入, 其余部分暂时放在
- 部分对换
- 可以将进程部分对换出内存,用以腾出内存空间, 对换出的部分暂时放在
swap space
- 可以将进程部分对换出内存,用以腾出内存空间, 对换出的部分暂时放在
SWAP SAPCE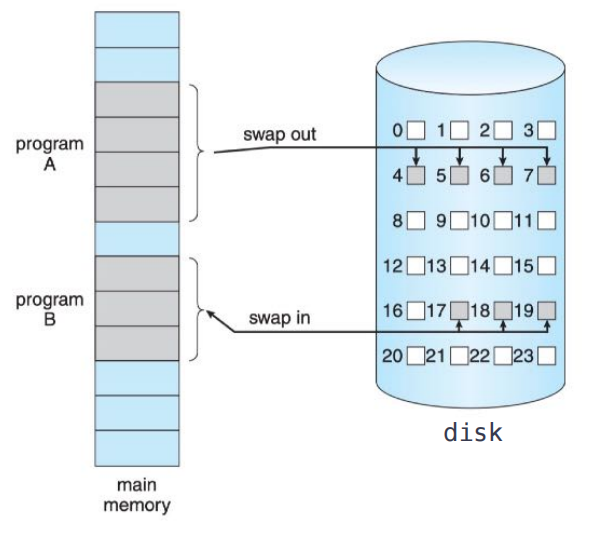
STORAGE HIERARCHY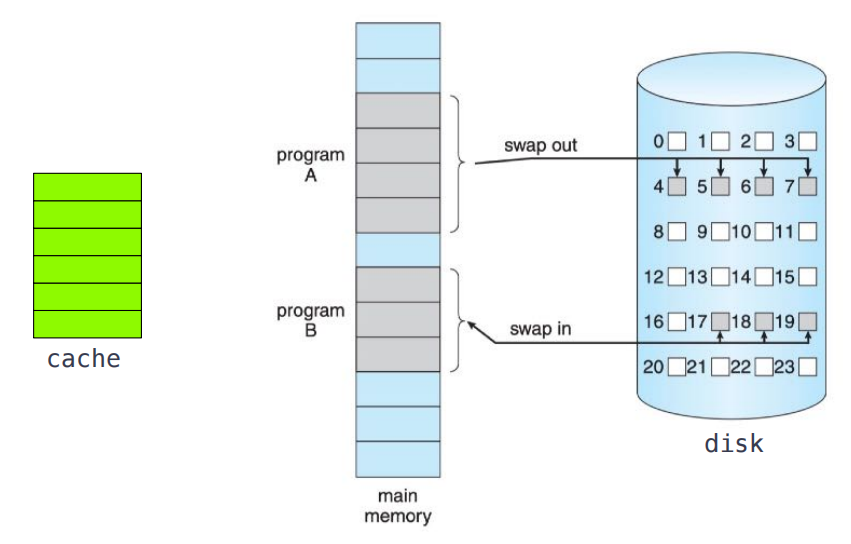
请求调页
DEMAND PAGING
- 使用按需分页的虚拟内存时,只有在程序执行过程中需要时才会加载页面. 因此从未被访问过的页面永远不会被加载到物理内存中。
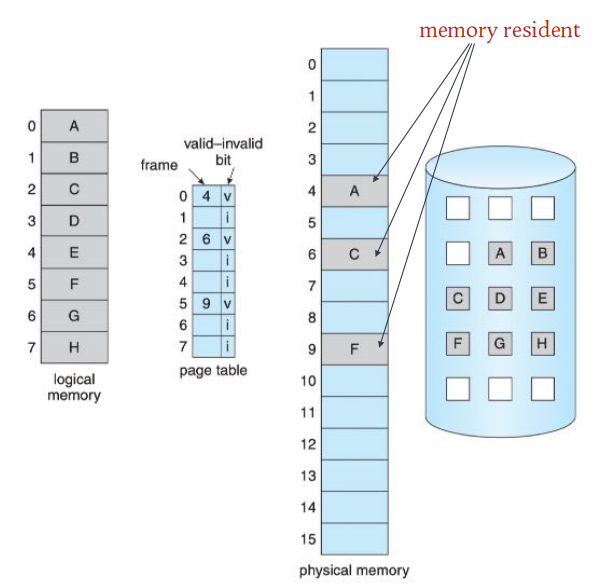
请求调页步骤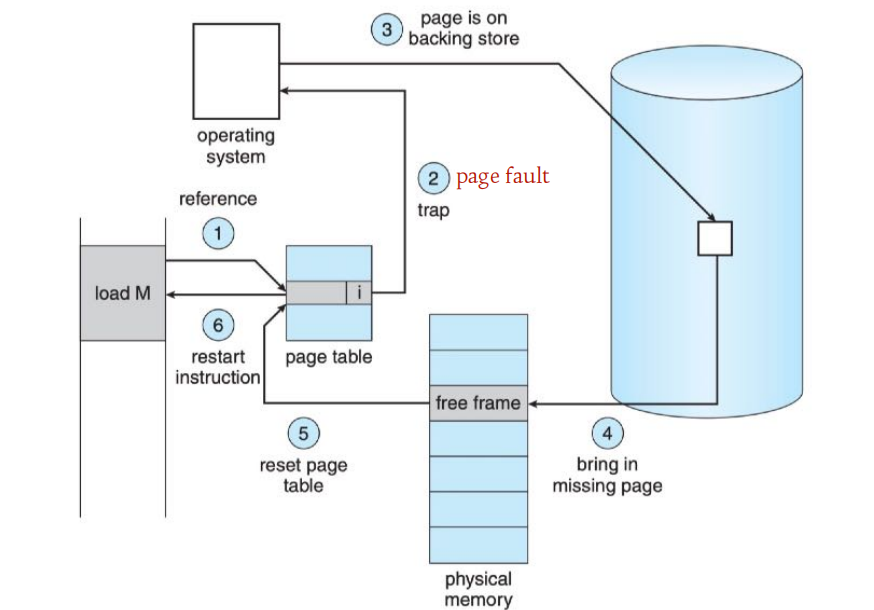
请求调页的性能
- 假设访问内存时间为ma,处理一次缺页中断的时间记作page fault time,令p为缺页中断的出现几率,则有效访问时间的计算公式为:
effective access time = $(1 − p) × ma + p × page fault time$
若ma=200ns,page fault time=8ms,p=0.001,则
effective access time = 8200ns - 缺页中断率p对性能影响重大
页面置换算法
页面置换
- 当进程在执行过程中发生了缺页,在请求调页的时候发现内存已经没有空闲页框可用,操作系统在此时会做出一个处理:页面置换。
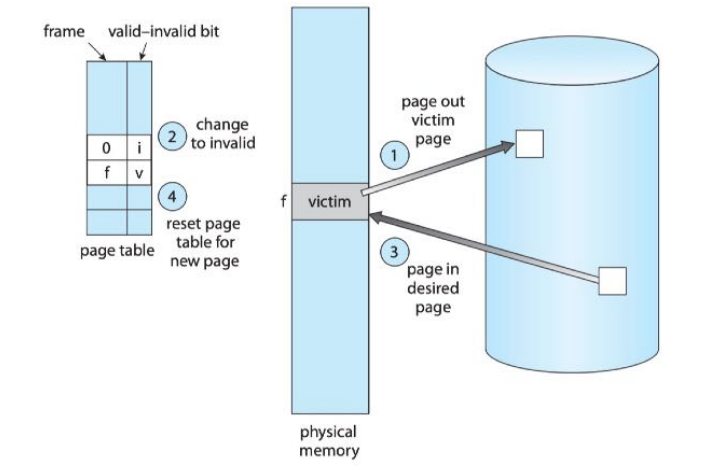
FIFO
- 总是淘汰最先进入内存的页面,因为它在内存中待的时间最久。
OPTIMAL
- 总是淘汰最长时间不会再使用的页面。
LRU(LEAST RECENT UNUSED)
- 总是淘汰最近最少使用的页面。
系统抖动
THRASHING
If the process does not have the number of frames it needs to support pages in active use, it will quickly page-fault. At this point, it must replace some page. However, since all its pages are in active use, it must replace a page that will be needed again right away. Consequently, it quickly faults again, and again, and again, replacing pages that it must bring back in immediately.
This high paging activity is called thrashing. A process is thrashing if it is spending more time paging than executing
抖动的原因
- 并发进程数量过多
- 进程页框分配不合理
PAGE FAULT FREQUENCY
PFF称作页面故障(频)率,基于这个数据可以实施一个防止抖动的策略:动态调节分配给进程的页框数量。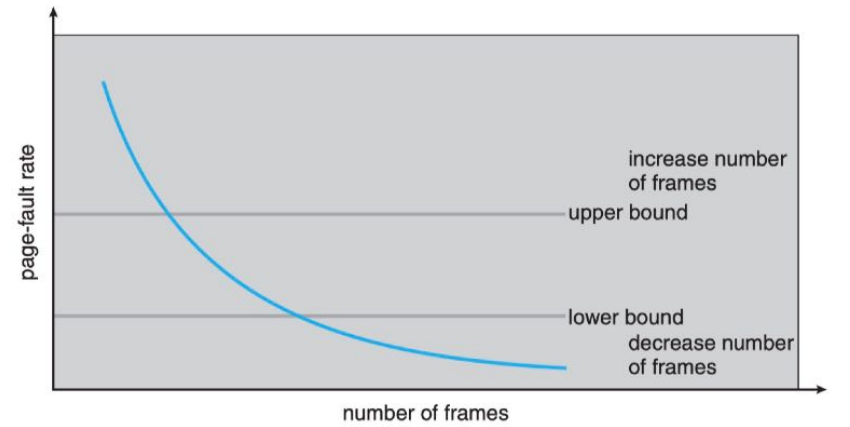
- Practically speaking, thrashing and the resulting swapping have a disagreeably large impact on performance.
- The current best practice in implementing a computer facility is to include enough physical memory, whenever possible, to avoid thrashing and swapping. (233)
- From smartphones through mainframes, providing enough memory to keep all working sets in memory concurrently, except under extreme conditions, gives the best user experience
Mass Storage
磁盘结构
MAGNETIC DISK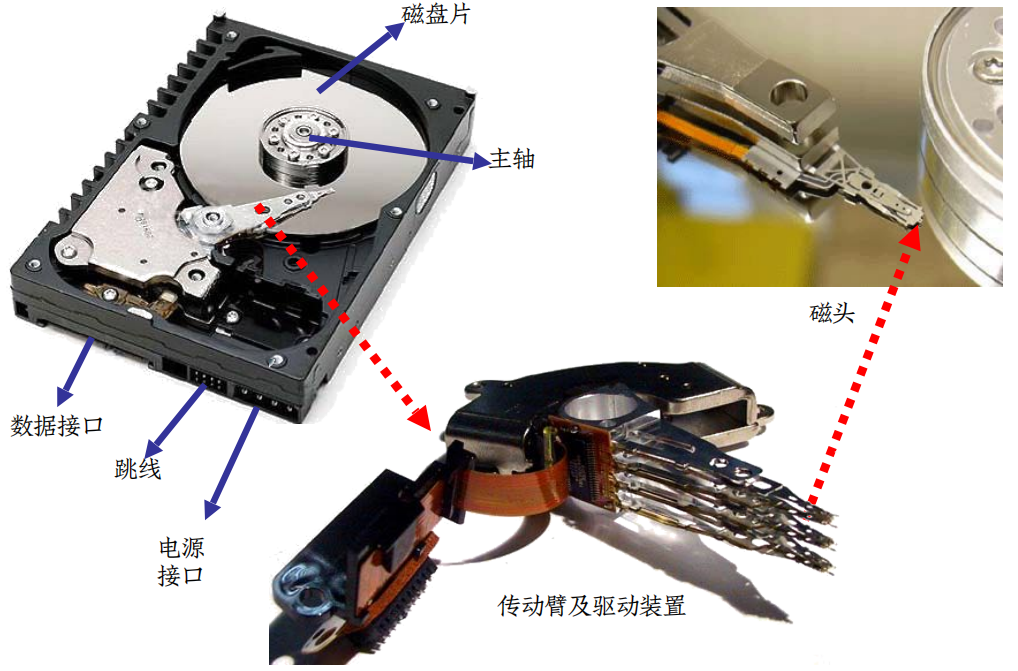
磁盘结构
- 磁道:能被磁头访问的一组同心圆
- 扇区:磁道上的区域,数据存放的基本单位
- 柱面:所有盘片同一磁头下的磁道集合
- 恒角速度
CAV(机械硬盘)- 不同磁道密度不同,但转速恒定
- 恒线速度
CLV(DVD,CD)- 每条磁道上的数据密度相等 磁道密度相同,但转速不断变化
磁盘格式化
- 低级格式化(
Low-level formatting)- Physical formatting
- 为每个扇区使用特殊的数据结构进行填充,包括一个头部、数据区域和一个尾部。
- 头部和尾部包含一些控制信息,如扇区号、ECC码等.
高级格式化(High-level formatting)
- Logical formatting
- 构建文件系统,在磁盘上初始化文件系统数据结构,如空闲和已分配空间表、一个空目录等.
磁盘性能
磁盘性能指标
- 查找一个物理块的顺序:柱面号、磁头号和扇区号
- 寻道时间Ts:将磁头定位到正确磁道(柱面)上所花的时间,与盘片直径和传动臂速度相关,平均20ms。
- 旋转延迟Tr:所查找的扇区转到磁头下所用的时间,与磁盘的旋转速度有关,一个10,000 r/m的磁盘平均旋转延迟为3ms。
- 传送时间T:传送扇区内的数据的时间,同样取决于磁盘的旋转速度,T = b/(rN) (b为要传送的字节数,N为一个磁道中的字节数,r为转速)
- 总的平均存取时间 $Ta = Ts + Tr + T$
磁盘调度
DISK I/O REQUEST
- Whenever a process needs I/O to or from the disk, it issues a system call to the operating system. The request specifies several pieces of information:
- Whether this operation is input or output
- What the disk address for the transfer is
- What the memory address for the transfer is
- What the number of sectors to be transferred is
DISK SCHEDULING
For a multiprogramming system with many processes, the disk queue may often have several pending requests. Thus, when one request is completed, the operating system chooses which pending request to service next.
FCFS SCHEDULING(先来先服务)

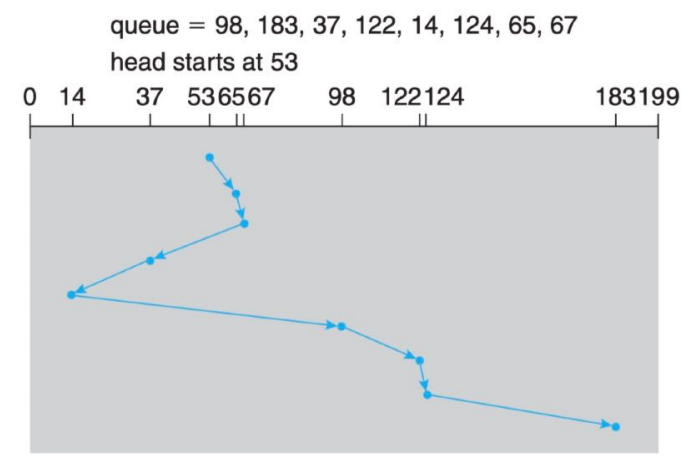
SSFT SCHEDULING(最短寻道时间优先)
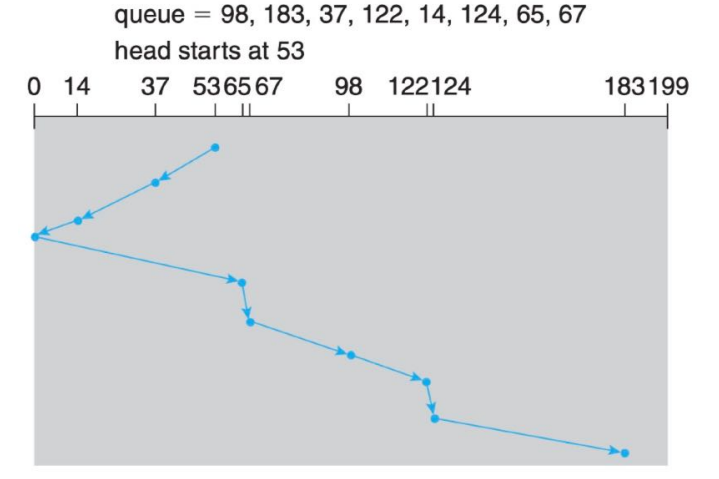
SCAN SCHEDULING(扫描算法)
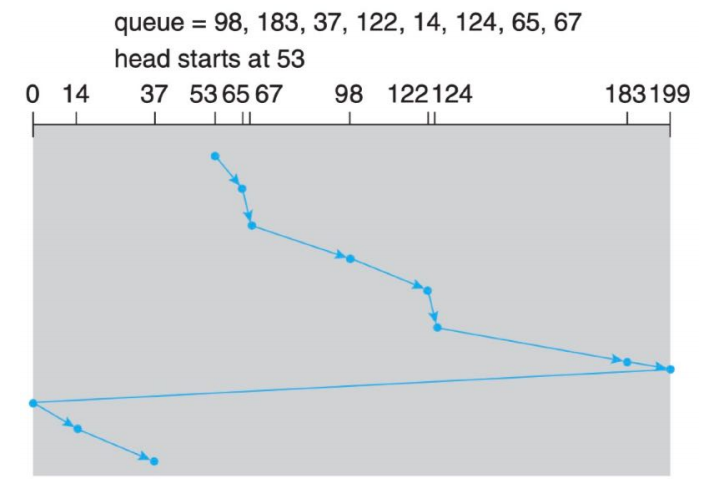
C-SCAN SCHEDULING(循环扫描算法)
LOOK SCHEDULING
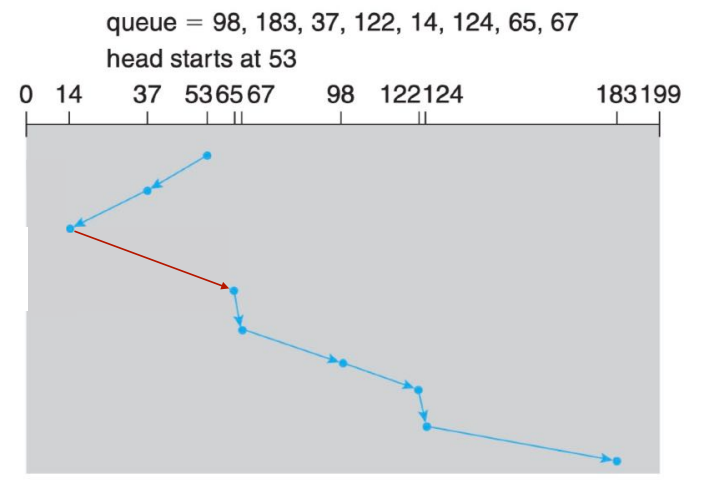
SELECTION OF A ALGORITHM
- FCFS is the simplest.
- SSTF is common and has a natural appeal but it may cause a starvation problem.
- SCAN and C-SCAN perform better for systems that place a heavy load on the disk.
LINUX I/O SCHEDULER
- noop:it performs FCFS policy which is good enough for SSD.
- deadline:it works by creating two queues: a read queue and a write queue. Each I/O request has a time stamp associated that is used by the kernel for an expiration time. When an I/O request reaches its deadline, it is pushed to the highest priority.
- cfq:Complete Fairness Queueing works by creating a per-process I/O queue. The goal of this I/O scheduler is to provide a fair I/O priority to each process. While the CFQ algorithm is complex, the gist of this scheduler is that after ordering the queues to reduce disk seeking, it services these per-process I/O queues in a round-robin fashion.
File System
文件系统
- For most users, the file system is the most visible aspect of an operating system.
- It provides the mechanism for on-line storage of and access to both data and programs of the operating system and all the users of the computer system.
- File systems live on devices, such as magnetic disk, SSDs.
- The file system consists of two distinct parts: a collection of files, each storing related data, and a directory structure, which organizes and provides information about all the files in the system.
文件概念
文件定义
- 文件(File)是信息的逻辑存储单位。
- 在用户看来,文件是具有结构的信息集合
- 在系统看来,文件的本质是存储在外存当中的二进制集合
- 文件可以存储不同类型的信息,如文本文件、可执行文件、
doc文档文件、xls表格文件等
文件属性
- 文件是”按名存取”的
- 文件名
- 文件类型
- 位置
- 大小
- 时间、日期和用户标识
- 保护
文件类型
- 文件类型可用于指示文件的内部结构,操作系统通过了解文件类型决定对文件如何进行解释。
- 一般地,操作系统至少要能解释两种文件类型:
- 文本文件
- 二进制可执行文件
Unix认为每个文件由字节序列构成,解释这些字节的工作交给对应的应用程序完成
访问方法
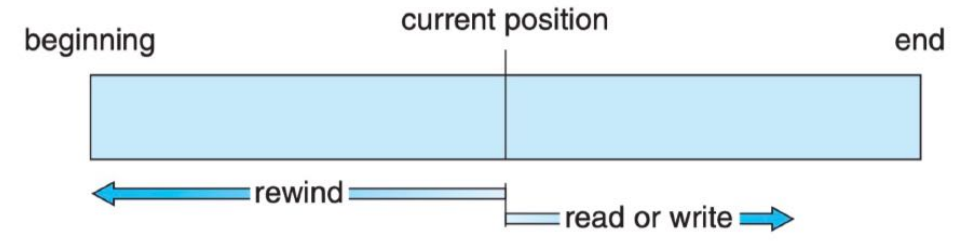
顺序访问
- 这种访问文件的方式最为常见,文件信息按顺序排序,读取/写入当前文件信息后,将文件指针移向下一个邻接区域。
- 磁带模型
直接访问
- 若文件的逻辑记录(logical record)的长度固定,那么允许在访问文件信息时可按任意顺序进行快速读取和写入。
- 磁盘模型 假设逻辑记录长度为L,若要访问某个文件的第N个逻辑记录(编号从0开始),则可转换成:”访问从文件起始位置L*N开始的L字节”
文件目录
DIRECTORY
- The directory can be viewed as a symbol table that translates file names into their directory entries.
- Search for a file
- Create a file
- Delete a file
- List a directory
- Rename a file
- Traverse the file system
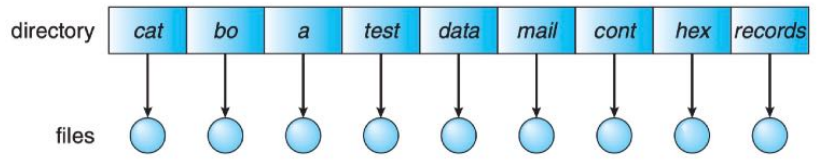
SINGLE-LEVEL DIRECTORY
- The simplest directory structure is the single-level directory. All files are contained in the same directory, which is easy to support and understand.
- However, naming a file is a big problem.
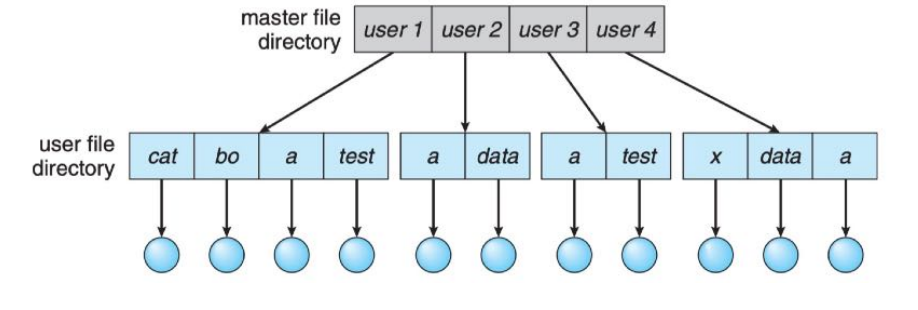
TWO-LEVEL DIRECTORY
- In the two-level directory structure, each user has his own user file directory (UFD). The UFDs have similar structures, but each lists only the files of a single user. When a user job starts or a user logs in, the system’s master file directory (MFD) is searched
TREE-STRUCTURED DIRECTORY
- Tree-structure allows users to create their own subdirectories and to organize their files
accordingly. - A tree has a root directory, and every file in the system has a unique path name.
- A directory (or subdirectory) contains a set of files or subdirectories.
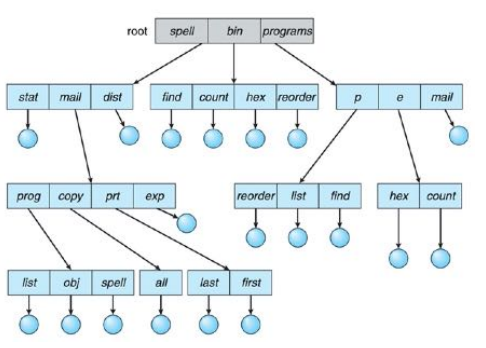
共享与保护
用户和组
- 大多用户系统中,提出了文件共享和保护的需求。
- 在文件和目录的属性加入了”用户”和”组”两个概念:
- User:即为所有者(Owner)
- Group:用户集合,他们拥有相同的访问权限
文件访问控制
- 为每个文件和目录关联一个访问控制列表(Access Control List)可以实现基于身份的访问控制。以Linux为例:
- 每个文件/目录有三种用户类型:Owner/Group/Other
- 三种用户的访问控制权限均有readable/writable/executable (
rwx) - 每个文件/目录的ACL有9个bit来指示它的访问控制权限
文件系统实现
文件目录
文件控制块
- 文件系统通过文件控制块(
File Control Blcok)来维护文件结构,FCB包含有关文件的信息,包括所有得、权限、文件内容的位置等。 - 文件目录用于组织文件,每个目录项对应一个
FCB. - 文件目录实现的关键
FCB与文件内容的关联方法- 在目录中”按名”搜索的效率
INODES
UFS中的FCB被称作索引结点inode,每个inode都有一个唯一的编
号,包含的内容有:- The type of the file
- The mode of the file (ACL)
- The number of hard links to the file
- The user ID of the owner of the file
- The group ID to which the file belongs
- The number of bytes in the file
- An array of 15 disk-block addresses
- The date and time the file was last accessed
- The date and time the file was last modified
- The date and time the file was created
分配方法
连续分配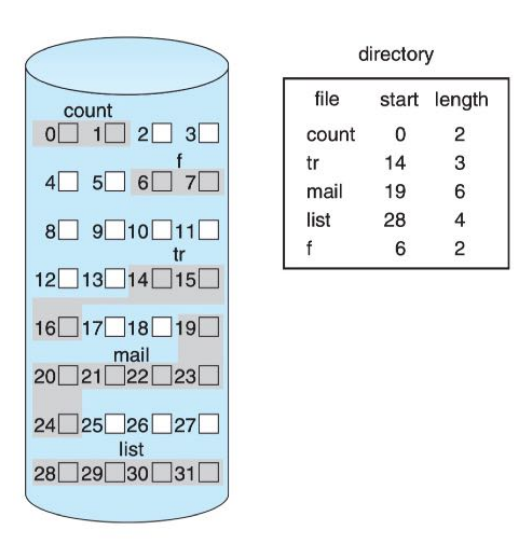
- 每个文件在磁盘上占用连续的物理块
链接分配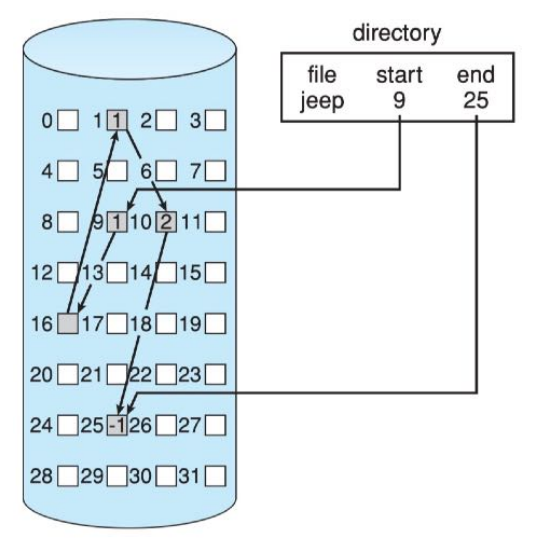
- 文件所占用的物理块分散在磁盘的不同位置,通过指针将它们链接起来。
簇CLUSTER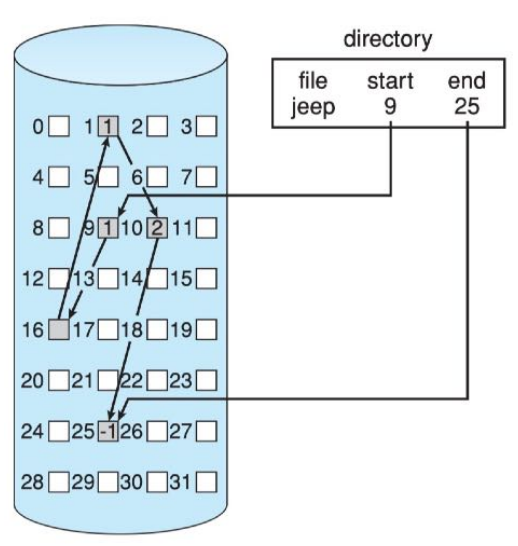
- 簇(
Cluster)指一组物理块的集合。如果以簇作为分配单位,可以节省指针占用的空间比例
FILE ALLOCATION TABLE
- 文件分配表
FAT是一个典型的链接分配方案,不过它没有在物理块或簇的尾部加入指针,而是用一张表来记录文件占用物理块号的顺序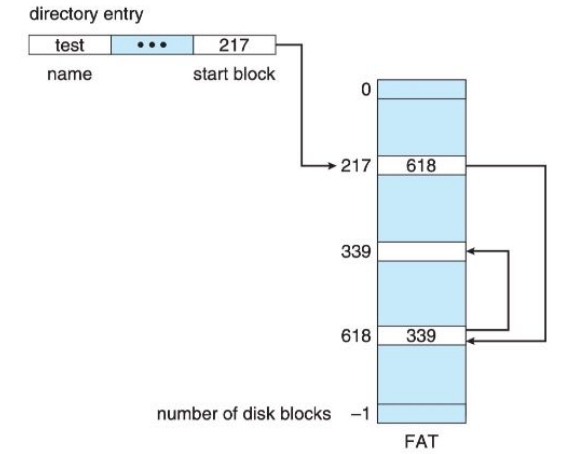
索引分配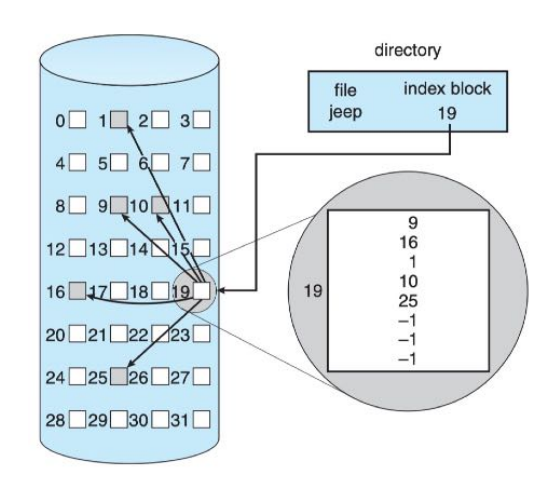
- 将文件占用的所有物理块号按逻辑顺序保存在一张索引表中,存有索引表的物理块称索引块(
index block)
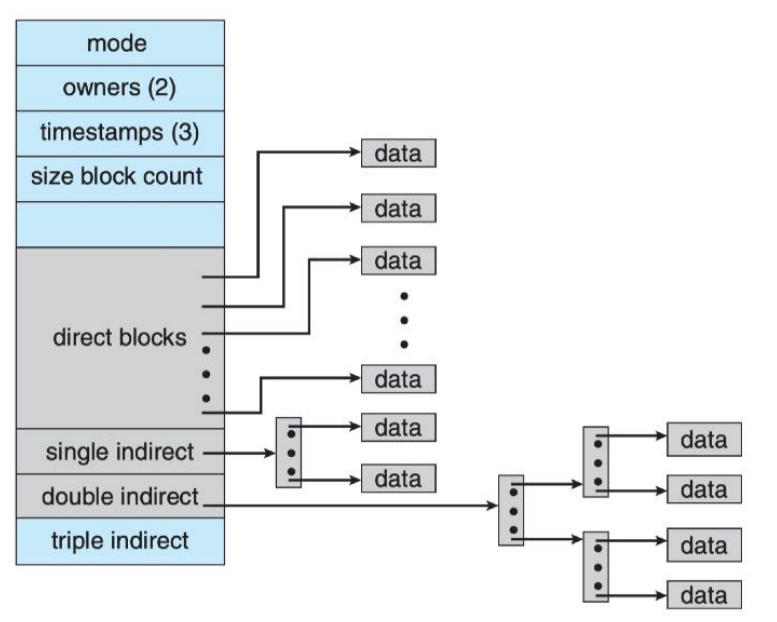
UFS的索引块
- 每个文件都要有一个索引块,
UFS的每个索引块有15个物理块地址- 0~11:direct block
- 12:single indirect block
- 13:double indirect block
- 14:triple indirect block
空闲空间管理
BIT MAP
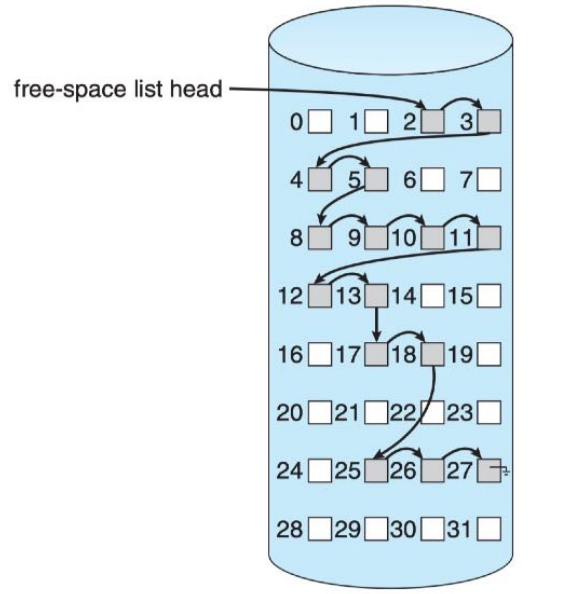
- Frequently, the free-space list is implemented as a bit map or bit vector. Each block is represented by 1 bit. If the block is free, the bit is 1; if the block is allocated, the bit is 0.
LINKED LIST
- Another approach to free-space management is to link together all the free disk blocks, keeping a pointer to the first free block in a special location on the disk.
文件系统结构
LAYERED FILE SYSTEM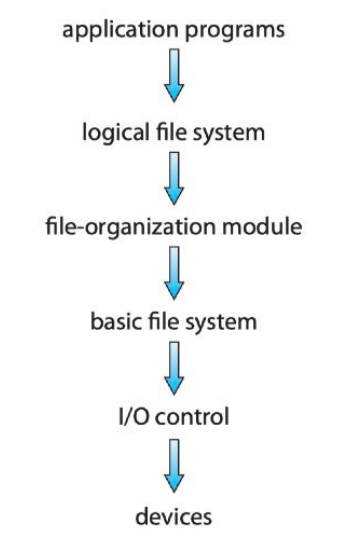
- 你发出一个读写A文件X位置数据的请求,系统从目录中找到这个文件并读出相应的
FCB,按照既有的分配方案计算X位置所在的物理块号,编制一个对该物理块号的读写请求,然后发给磁盘控制器.
VIRTUAL FILE SYSTEM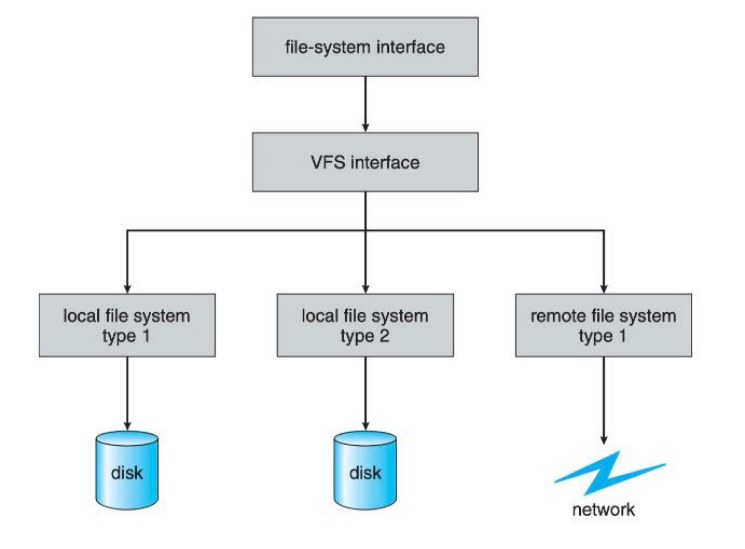
I/O Systems
I/O硬件
MOTHER BOARD
BUS
- 总线: 一组线路和通过线路传输信息的一个协议
- 并行:
Multiple Lane - 串行:
Single Lane
- 并行:
PERIPHERALS COMPONENT INTERCONNECT
PORTS
- PCIe
- SATA
- USB (
Universal Serial Bus) - VGA
- HDMI
- DVI
- Thunder Blot
设备类型
- 块设备(
block device)- 存取单位是一个
block - 如磁盘、磁带、
DVD等
字符设备(character device) - 存取单位是一个字符
- 如显示器、键盘、鼠标等
- 存取单位是一个
计算机中的IO系统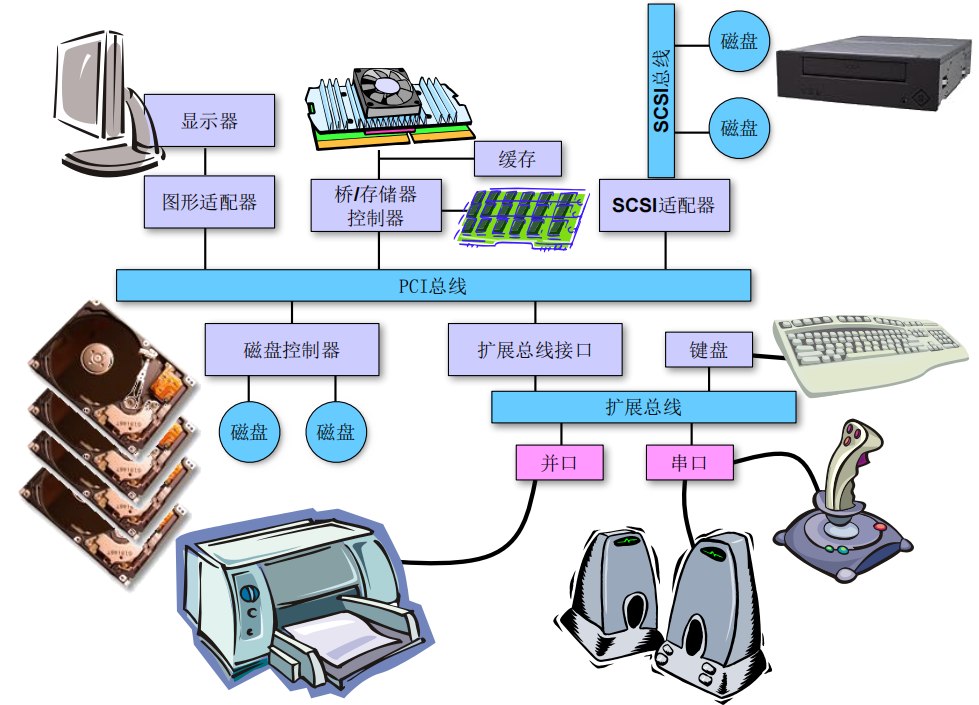
CONTROLLER
- A controller is a collection of electronics that can operate a port, a bus, or a device.
- A serial-port controller is a simple device controller. It is a single chip (or portion of a chip) in the computer that controls the signals on the wires of a serial port.
- A SCSI bus controller is NOT simple because the SCSI protocol is complex. It typically contains a processor, microcode, and some private memory to enable it to process the SCSI protocol messages.
- Some devices have their own built-in controllers. You will see a circuit board attached to one side of a disk drive. This board is the disk controller. It implements the disk side of the protocol for some kind of connection— SCSI or Serial Advanced Technology Attachment (SATA), for instance. It has microcode and a processor to do many tasks, such as bad-sector mapping, prefetching, buffering, and caching
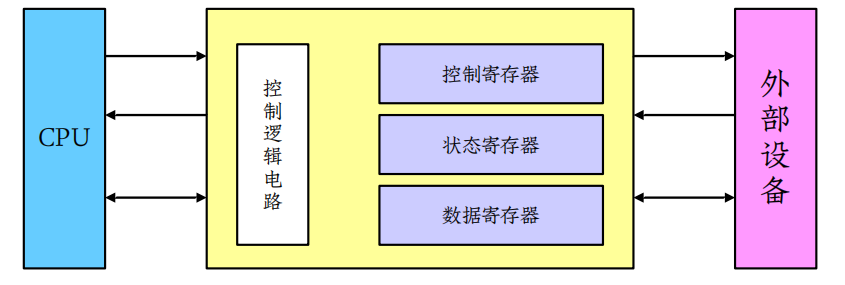
如何对控制器发布命令
- 控制器有一个或多个用于数据和控制信号的寄存器.
CPU通过读写这些寄存器来控制通信。- 控制寄存器:可以被主机发布命令或改变设备状态
- 状态寄存器:包含一些主机可读的位信息
- 数据寄存器:记录主机可读或写入的数据
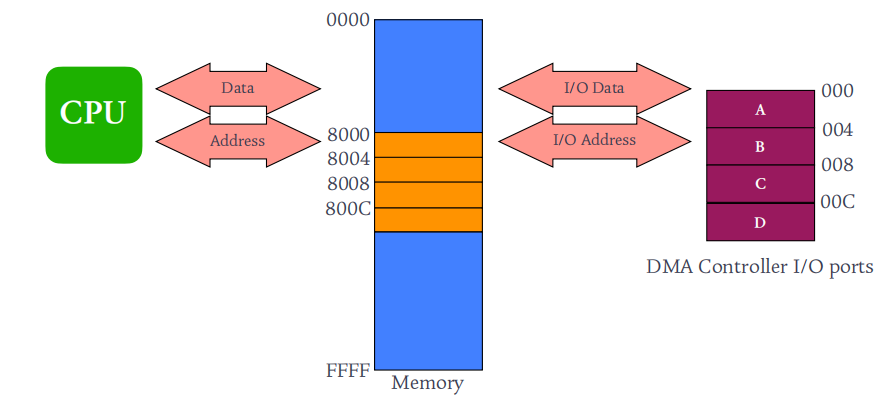
I/O地址
I/O地址:控制寄存器地址- 编址方式
I/O独立编址:使用独立的I/O指令,如IN、OUT- 内存映射编址:划出一块内存地址,将
I/O的端口地址映射进来,这样就可以使用访问内存指令对控制寄器进行读写。
I/O控制方式
轮询
- 重复测试
busy位,直到清零; - 设置控制寄存器为
write操作,并将要写入的字节X存 - 入数据寄存器;
- 设置
ready位 - 若
ready位为1,则设置busy位 - 执行
write命令,将字节X写入设备 - 清除
ready位和busy位
中断
DMA直接内存访问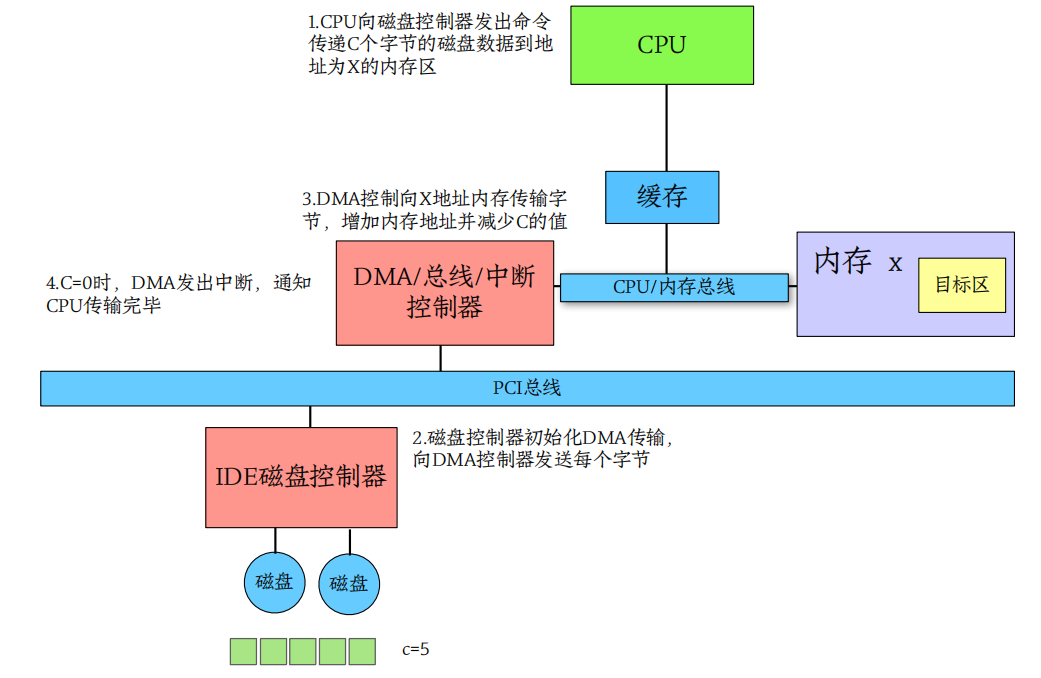
CYCLE STEALING
When the DMA controller seizes the memory bus, the CPU is momentarily prevented from accessing main memory. We call the DMA steals the CPU’s cycle.
Although this cycle stealing can slow down the CPU computation, offloading the data-transfer work to a DMA controller generally improves the total system performance
内核I/O结构
- 内核
I/O结构包括I/O硬件和I/O软件两个部分,I/O软件的设计目标主要体现在:- 高效率(
efficiency):通过一些手段提高I/O设备的访问效率。 - 通用性(
generality):屏蔽硬件细节,让用户使用统一的接口方便地使用不同的硬件。
- 高效率(
内核I/O结构图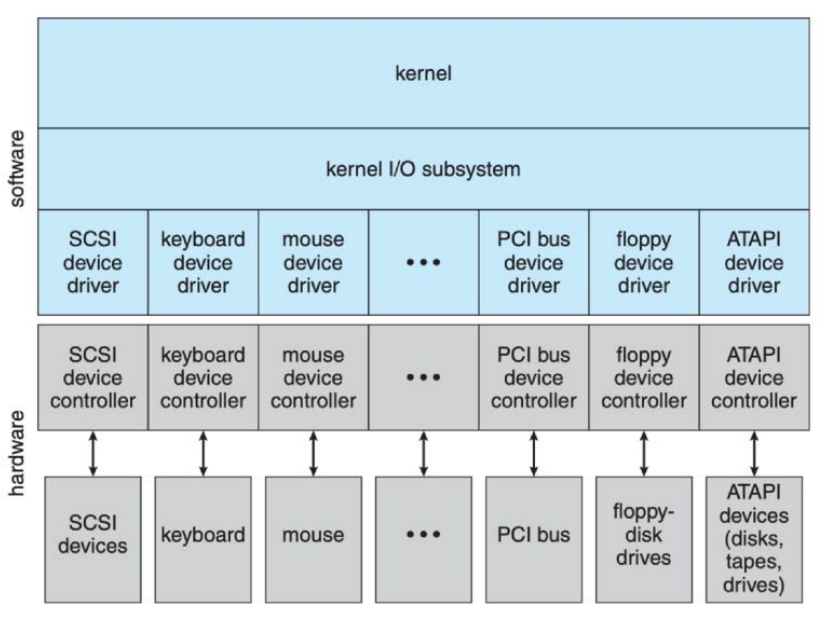
设备驱动层
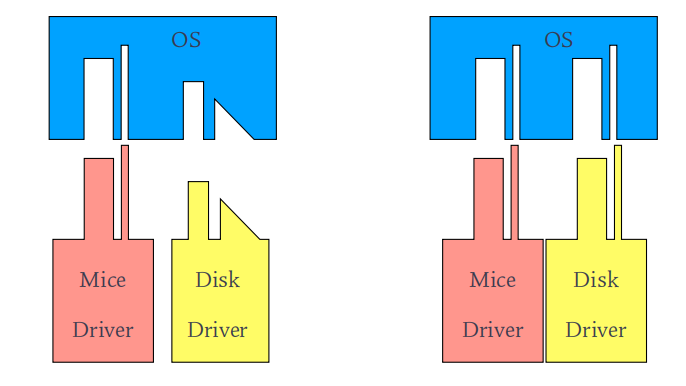
- Device-driver layer makes the I/O subsystem independent of the hardware through hiding the differences among device controllers
内核I/O子系统
Several services—scheduling, buffering, caching, spooling, device reservation, and error handling—are provided by the kernel’s I/O subsystem and build on the hardware and device-driver infrastructure.
The I/O subsystem is also responsible for protecting itself from errant processes and malicious users.
BUFFERING
- 缓冲主要用于处理数据流的生产者和消费者速度不匹配问题
BUFFER & CACHE
- The difference between a buffer and a cache is that a buffer may hold the only existing copy of a data item, whereas a cache, by definition, holds a copy on faster storage of an item that resides elsewhere.
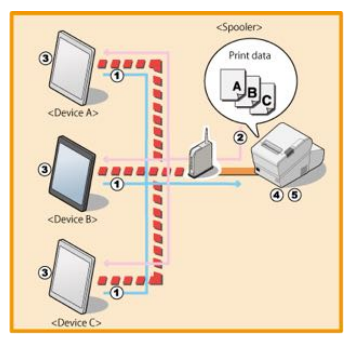
SPOOLING
- A spool (Simultaneous Peripheral Operations On-Line) is a buffer that holds output for a device, such as a printer, that cannot accept interleaved data streams. Although a printer can serve only one job at a time, several applications may wish to print their output concurrently, without having their output mixed together
I/O请求生命周期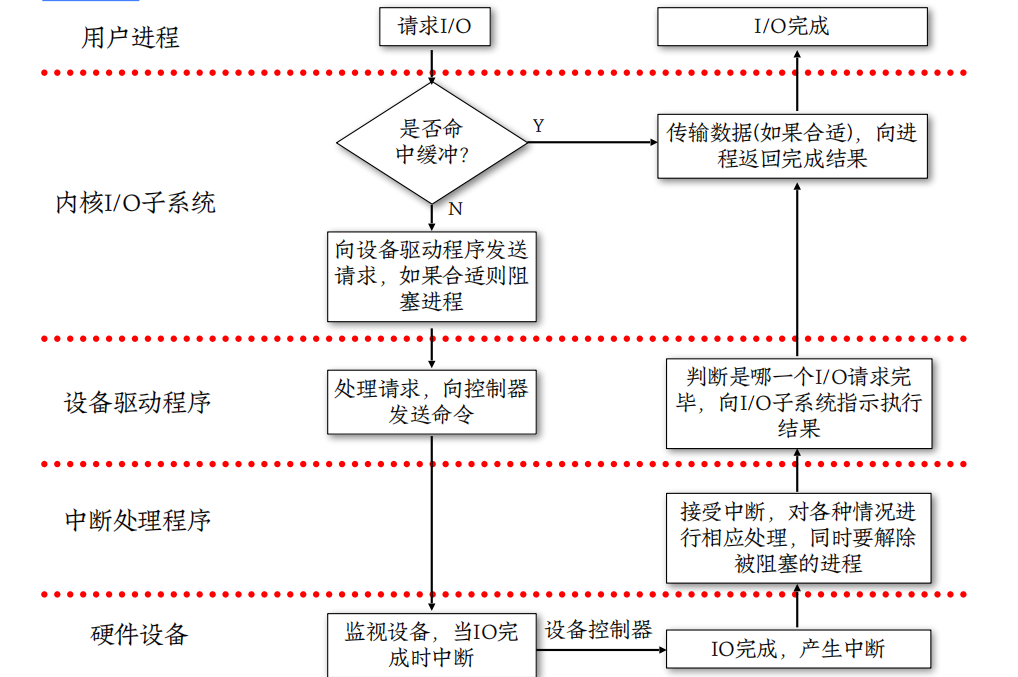
The End

Linux多线程编程
创建线程
1 | int pthread_create( |
- thread 保存新创建线程ID的变量地址值,线程与进程相同,也需要用于区分不同线程的ID
- attr 用于传递线程属性的参数,转递NULL时,创建默认属性的进程
- start_routine 相当于线程main函数的,在单独执行流中执行的函数地址值(函数指针)
- arg 传给线程启动函数的参数的地址
1 |
|
pthread_ create函数第一个参数指向一个虚拟内存单元,该内存单元的地址即为新创建线程的线程ID,属于本地线程库的范畴。线程库的后续操作,就是根据该线程ID来操作线程的。本地线程库提供了pthread_ self()函数,可以获得线程自身的ID:
1 | void* thread_run(void* args) |
线程终止
- 1.线程函数处进行return。
- 2.线程可以自己调用pthread_exit函数终止自己。
- 3.一个线程可以调用pthread_cancel函数终止同一进程中的另一个线程。
1 | void pthread_exit(void *ret); |
1 |
|
1 | int pthread_cancel(pthread_t thread); |
线程等待
1 | int pthread_join(pthread_t thread, void **retval); |
- 如果thread线程通过return返回,retval 所指向的单元里存放的是thread线程函数的返回值。
- 如果thread线程被别的线程调用 pthread_cancel 异常终止掉,retval 所指向的单元里存放的是常数PTHREAD_CANCELED,就是-1
- 如果thread线程是自己调用 pthread_exit 终止的,retval 所指向的单元存放的是传给 pthread_exit 的参数。
- 如果对thread线程的终止状态不感兴趣,可以传 NULL 给 retval 参数
线程分离
1 | int pthread_join(pthread_t thread, void **retval); |
- 默认情况下,新创建的线程是joinable的,线程退出后,需要对其进行pthread_join操作,否则无法释放资源,从而造成系统泄漏。
如果不关心线程的返回值,join是一种负担,这个时候,我们可以告诉系统,当线程退出时,自动释放线程资源。





