
Spark的基本使用
安装Anaconda
- 创建
.condarc文件添加镜像源 - 创建环境
conda create -n xxx python=3.7 - 查看安装环境列表
conda env list - 进入创建的环境
conda activate <环境名> - 退出环境
conda deactivate
Spark模块
Spark架构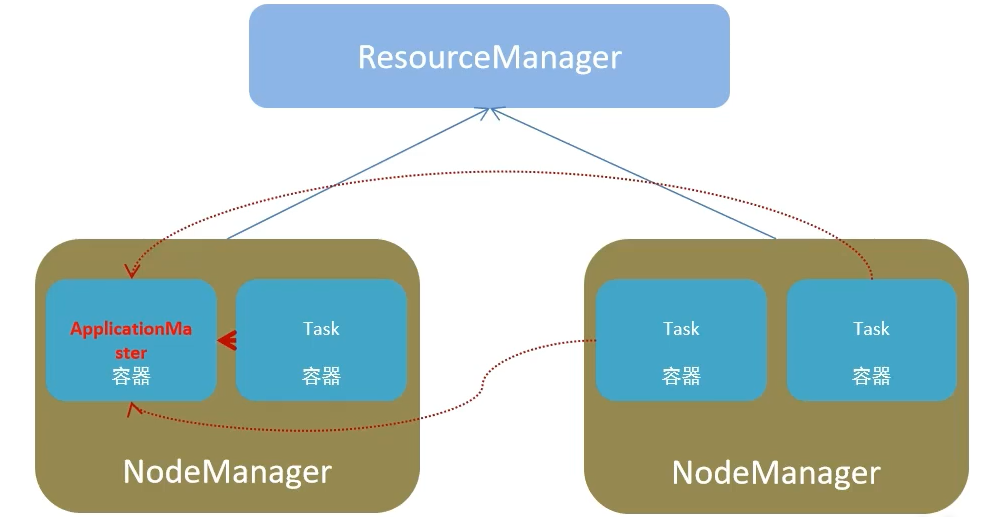
- 资源管理层面
- 集群资源管理者
Master - 单机资源管理者
Worker
- 集群资源管理者
- 任务计算层面
- 单任务管理者
Driver - 单任务执行者
Executor
- 单任务管理者
local模式
启动一个 JVM Process进程(包含多个线程)执行 Task
可以限制模拟 Spark集成环境的线程数量
* Local[N] or Local[*] (*按照cpu最多核心设置线程数)
StandAlone架构
StandAlone集群在进程上主要有3类进程:
* 主节点 Master: 管理整个集群资源,并托管运行各个任务的Dirver
* 从节点 Wokers: Woker角色管理每个机器的资源,分配对应的资源来运行 Executor(task)
* 历史服务器 HistoryServer(可选): 保存事件日志到HDFS
SparkOnYarn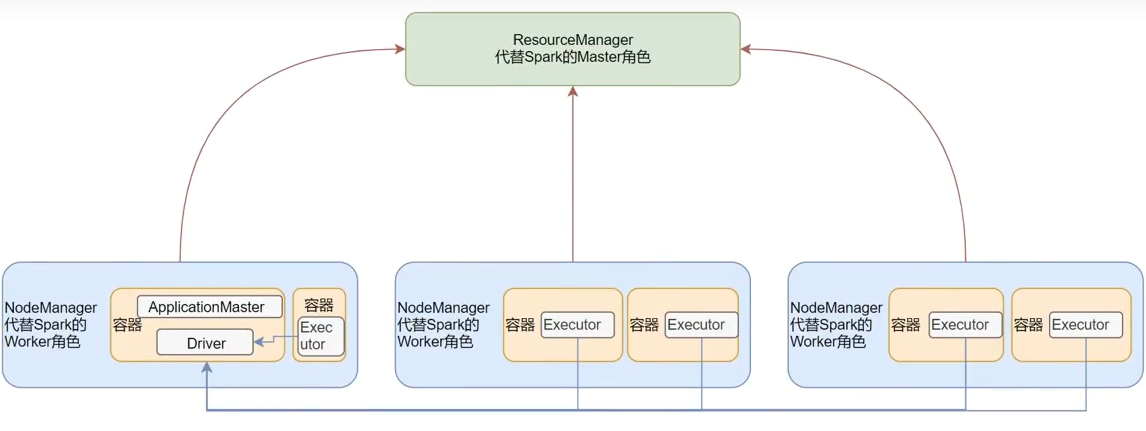
RDD
定义
Resilient Distributed Dataset 弹性分布式数据集
RDD算子
分布式集合上的 API 称为算子,可分成以下两类
Transformation
返回值仍然是RDD, 这种算子是lazy懒加载, 如果没有action算子,Transformation算子是不工作的Action算子
返回值不是RDD的算子
常用Transformation算子
map(func)flatMap(func)
对rdd执行map操作, 然后解除嵌套1
2lt = [[1,2,3], [4,5,6]]
# -> lt = [1,2,3,4,5,6]reauceByKey(func)1
# func(v, v) -> v
mapValues(func)
对二元组的value执行map操作groupBy(func)1
2
3
4
5
6
7from pyspark import SparkContext
if et _name__ == '__main__':
sc = SparkContext('local[*]', 'test')
rdd = sc.parallelize([('a',1), ('a',1), ('b', 1), ('c', 1)])
result = rdd.groupBy(lambda x: x[0])
print(result.map(lambda x: (x[0], list(x[1]))).collect())
#输出 [('b', [('b', 1)]), ('c', [('c', 1)]), ('a', [('a', 1), ('a', 1)])]groupByKey()Filter(func)1
# func(T) -> bool
distinct()去重union(other_rdd)合并join(other_rdd)内连接leftOuterJoin(other_rdd)左外连接rightOuterJoin(other_rdd)右外连接
只能作用于二元组, 根据key值进行关联
intersection(other_rdd)求交集glom按分区进行嵌套sortBy(func, ascending=True or False, numPartitions=num)- func(T) -> U
- True or False
- 用多少分区进行排序
sortByKey(ascending=True or False, numPartitions=num, keyfunc)
常用Action算子
conuntByKey()collect()
将RDD各个分区内的数据统一收集到Driver中形成一个List对象redece()fold()
带有初始值的聚合 (作用在分区内和分区外)first()取出第一个元素take(n)
将前n个元素以List形式返回top(n)
对结果进行降序排序, 取前n个元素takeSample(arg1, arg2, arg3)- arg2: 是否允许抽到同一个数据
- arg3: 抽样数量
- arg3: 随机数种子
takeOrdered(n, func)n: 取前n个数据- 对排序的数据进行更改(不会改变数据本身),默认为升序
foreach()
和map作用相同,但是没有返回值saveAsTextFile(path)
将RDD数据写入文本文件中mapPartition(func)
一次传递的数据是一整个分区的数据作为一个迭代器(一次性list)对象传入过来foreachPartition(func)partitionBy(n, func)- n: 重新分区后分区的数量
- func: 自定义分区规则
(x) -> int(k) (0 <= k < n)
repartition(n)
重新进行分区
RDD的缓存
rdd的数据是过程数据cache()缓存到内存中persist(StoregeLevel.MEMORY_ONLY)persist(StoregeLevel.MEMORY_ONLY_2)生成两个副本persist(StoregeLevel.DISK_ONLY)persist(StoregeLevel.MEMORY_AND_DISK)先放入内存,空间不够时放入硬盘
checkPoint仅支持硬盘存储 (不保留血缘关系)
广播变量
1 | #将本地变量v标记成广播变量 |
累加器
1
cnt = ac.accumulator(初始值)
简单示例
1 | from pyspark import SparkContext |
SparkSQL
DataFrame的组成
- 结构层面
- StructType (表结构)
- StructField (列信息)
- 数据层面
- Row
- Column
创建 DataFrame
1 | from pyspark.sql import SparkSession |
1 | from pyspark.sql import SparkSession |
通过SparkSQL的统一 API 进行数据读取构建
sparksession.read.format(“text|csv|json|…”)
.option(“k”, “V”) 可选
.schema(“StructType | String”)
.load(“path”)
text1
2
3
4schema = StructType().add("data", StringType(), nullable=True)
df = spark.read.format("text").\
schema(schema=schema).\
load("file:///home/yuki/SparkSQL/info.txt")json1
df = spark.read.format("json").load("path")





